Article from www.guardian.co.uk
Imprezzeo is initially targeting the business-to-business market with its image search but sees even bigger potential with retail, social media and dating sites
There's huge, untapped potential in the image search sector, according to the business-to-business service Imprezzeo. Backed by Independent News & Media. Imprezzeo is initially targeting news agencies, photo-sharing sites and commercial photo libraries but thinks the bigger potential could include retail, social media and even dating sites - all of whom would benefit from searching by image, rather than text, says chief executive Dermot Corrigan.
Set up in October 2007 and launched in beta one year later, Imprezzeo employs seven staff in London and at its development base in Sydney, Australia.
 Imprezzeo chief executive Dermot Corrigan
Imprezzeo chief executive Dermot Corrigan
• Explain your business to my Mum
"Imprezzeo allows users to click on images to find other similar images. Think of it as a 'more like this' feature for photos and pictures. It does not rely on the text associated with an image to find similar stuff but the actual content of the image itself. So by selecting or uploading a relevant example, your mum can find the image she wants on a photo-sharing site, a search engine or even a retail site, much more accurately and much faster.
"Most image or picture searches use text tags to produce their results which means you have to sift through pages of irrelevant results to get what you want. Imprezzeo uses a combination of content-based image retrieval and facial recognition technology that identifies images that closely match a sample. So you pick an image that is close to what you want from the initial search results, or you can upload your own, and the technology will find other similar images."
• How do you make money?
"We sell our search technology to companies that have large image libraries - newspapers, stock libraries and so on - but we're talking to all sorts of companies to develop tools for a whole range of markets beyond that: retailers, for example, can use it to recommend products (if you liked this red bag, you might also like these similar products) and search engines can use it to improve the search experience. We're even looking at rolling out an application to let consumers better search and organise their personal photo collections, online or on the desktop."
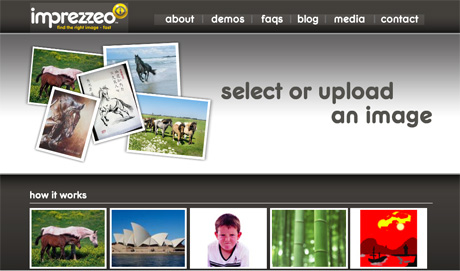 Imprezzeo image search
Imprezzeo image search
• How many users do you have now, and what's your target within 12 months?
"We launched our beta product in October 2008 and have a number of trials going on in our initial target market segments. When these go live that will expose us to many millions of users. 2009 though will see us move beyond these segments into those suggested above and so we are optimistic 2009 should see Imprezzeo become the major power behind image search on the web.
• What's your background?
"Mainly in large media businesses - information, news and communications. I started out at Frost & Sullivan, the technology market analyst firm and then moved into the news business with PR Newswire. At LexisNexis I ran the news aggregation business and led a number of its initiatives in technology-led markets. Before Imprezzeo I worked with a number of digital media businesses, which I still have interests in, and did a stint doing some strategic consultancy for Wolters Kluwer, a large publishing, software and services group."
• How do you plan to survive the downturn?
"We're keeping the business lean and focusing on clear sales targets. We're in a strong position as we can prove value and return-on-investment to prospects.
"I'd argue that web businesses in the main will fare better than many others I could mention. There will be casualties but we have some very talented people and three other very important assets: a sound revenue model, a compelling value proposition and technology with a definite 'wow' factor."
• What's your biggest challenge?
"Not taking on too much too quickly. The potential applications for this are huge, and we're always thinking about the next stage of development."
• Name your closest competitors
"Idee do something similar (though we see their focus as on image recognition rather than proximity search) and I have no doubt this is a development area for the big web search players. It may in the end come down to who has the best mousetrap and right now I think that's us."
• Which tech businesses or web thinkers are the ones to watch?
"While I have to declare an interest as one of the backers of strategyeye.com, I do think it is essential intelligence if you want to know what's what in the digital media world. I tend to appreciate sites for their utility rather than fun which explains why LinkedIn continues to impress (as much as a business development tool as anything else) and Videojug is essential. Like.com is pioneering visual search for online shopping in the US which is all to the good for a company like us and it looks like 'social investing' (in the sense of observing the investment decisions of other as opposed to ethical investment) has arrived with covestor.com - one for the long haul though."
• Who's your mentor?
"I've had a number who have been positive influences in my career. Arsene Wenger inspires me as much as any of them."
• How's you work/life balance?
"Having three children means that you have to keep a balance. My wife understands what we are trying to achieve here so she takes the trips to Australia in her stride (less so when she finds out I also get to spend time with a friend who lives in Bondi). While I work long hours, working at weekends tends to be a no-no."
• What's the most important piece of software or web tool that you use each day?
"Google desktop search."
• Where do you want the company to be in five years?
"Providing the benchmark for image search. Once people realise what they can do to find images, they won't accept the old way of doing things any more."
imprezzeo.com
http://www.guardian.co.uk/media/pda/2009/aug/26/image-searchengines






 Andrew Davidhazy, Tape-dispenser as seen in colour when placed between polarizers, 2005
Andrew Davidhazy, Tape-dispenser as seen in colour when placed between polarizers, 2005 This competition is about learning, or otherwise developing, the best controller (agent) for a version of Super Mario Bros.
This competition is about learning, or otherwise developing, the best controller (agent) for a version of Super Mario Bros. 