
Abstract: In this paper we propose and evaluate a new technique that localizes the description ability of several global descriptors. We employ the SURF detector to define salient image patches of blob-like textures and use the MPEG-7 Scalable Color (SC), Color Layout (CL), Edge Histogram (EH) and the Color and Edge Directivity Descriptor (CEDD) descriptors to produce the final local features’ vectors named SIMPLE-SC, SIMPLE-CL, SIMPLE-EH and SIMPLE-CEDD or “LoCATe” respectively. In order to test the new descriptors in the most straightforward fashion, we use the Bag-Of-Visual-Words framework for indexing and retrieval. The experimental results conducted on two different benchmark databases, with varying codebook sizes revealed an astonishing boost in the retrieval performance of the proposed descriptors compared both to their own performance (in their original form) and to other state-of-the-art methods of local and global descriptors.
A set of local image descriptors specifically designed for image retrieval tasks
Image retrieval problems were first confronted with algorithms that tried to extract the visual properties of a depiction in a global manner, following the human instinct of evaluating an image’s content. Experimenting with retrieval systems and evaluating their results, especially on verbose images and images where objects appear with partial occlusions, showed that the accepted correctly ranked results are positively evaluated by the extraction of the salient regions of an image, rather than the overall depiction. Thus, a representation of the image by its points of interest proved to be a more robust solution. SIMPLE descriptors, emphasize and incorporate the characteristics that allow a more abstract but retrieval friendly description of the image’s salient patches.
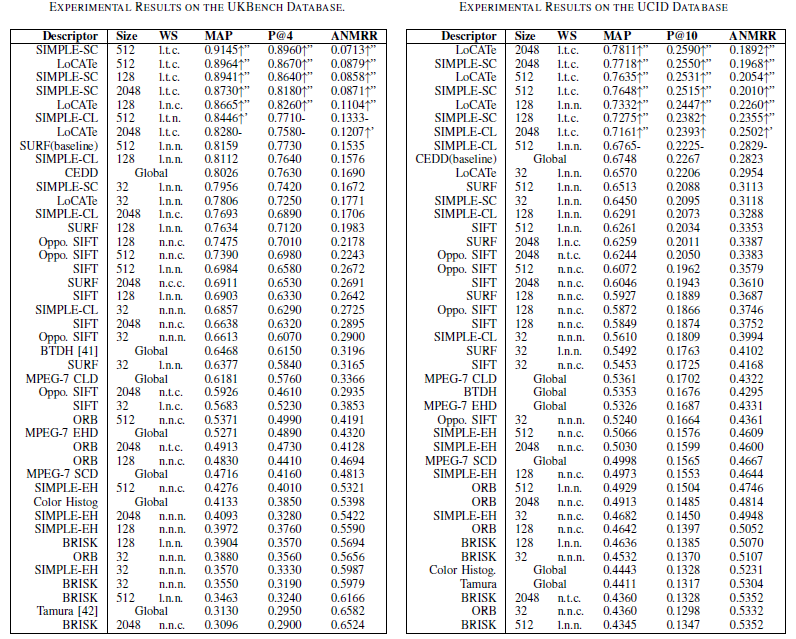
Experiments were contacted on two well-known benchmarking databases. Initially experiments were performed using the UKBench database. The UKBench image database consists of 10200 images, separated in 2250 groups of four images each. Each group includes images of a single object captured from different viewpoints and lighting conditions. The first image of every object is used as a query image. In order to evaluate our approach, the first 250 query images were selected. The searching procedure was executed throughout the 10200 images. Since each ground truth includes only four images, the P@4 evaluation method to evaluate the early positions was used.
In the sequel, experiments were performed using the UCID database. This database consists of 1338 images on a variety of topics including natural scenes and man-made objects, both indoors and outdoors. All the UCID images were subjected to manual relevance assessments against 262 selected images.
In the tables that illustrate the results, wherever the BOVW model is employed, only the best result achieved by each descriptor with every codebook size, is presented. In other words, for each local feature and for each codebook size, the experiment was repeated for all 8 weighting schemes but only the best result is listed in the tables. Next to the result, the weighting scheme for which the result was achieved is noted (using the System for the Mechanical Analysis and Retrieval of Text – SMART notation)
Source Code and more details are available at http://chatzichristofis.info/?page_id=1479
Details regarding these descriptors can be found at the following paper: (in other words, if you use these descriptors in your scientific work, we kindly ask you to cite the following paper )
C. Iakovidou, N. Anagnostopoulos, Y. Boutalis, A. Ch. Kapoutsis and S. A. Chatzichristofis, “SEARCHING IMAGES WITH MPEG-7 (& MPEG-7 Like) POWERED LOCALIZED DESCRIPTORS: THE SIMPLE ANSWER TO EFFECTIVE CONTENT BASED IMAGE RETRIEVAL”, «12th International Content Based Multimedia Indexing Workshop», June 18-20 2014, Klagenfurt – Austria (Accepted for Publication)
No comments:
Post a Comment