Considering several requests, the submission deadline has been extended to November 30th.
In addition to the Content-Based Multimedia Indexing (CBMI) 2014 workshop, a special issue of Multimedia Tools and Applications is devoted to Content Based Multimedia Indexing. The issue is not restricted to papers accepted to the workshop, but all papers submitted should contain sufficient innovative material with respect to previously published work.
Multimedia indexing systems aim at providing easy, fast and accurate access to large multimedia repositories. Research in Content-Based Multimedia Indexing covers a wide spectrum of topics in content analysis, content description, content adaptation and content retrieval. Various tools and techniques from different fields such as Data Indexing, Machine Learning, Pattern Recognition, and Human Computer Interaction have contributed to the success of multimedia systems.
Although, there has been a significant progress in the field, we still face situations when the system shows limits in accuracy, generality and scalability. Hence, the goal of this special issue is to bring forward the recent advancements in content-based multimedia indexing. Submitted papers should contain significant original new information and ideas. Topics of interest for the Special Issue include, but are not limited to:
Visual Indexing
• Visual indexing (image, video, graphics)
• Visual content extraction
• Identification and tracking of semantic regions
• Identification of semantic events
Audio and Multi-modal Indexing
• Audio indexing (audio, speech, music)
• Audio content extraction
• Multi-modal and cross-modal indexing
• Metadata generation, coding and transformation
• Multimedia information retrieval
Multimedia retrieval (image, audio, video …)
• Matching and similarity search
• Content-based search
• Multimedia data mining
• Multimedia recommendation
• Large scale multimedia database management
Multimedia Browsing and Presentation
• Summarization, browsing and organization of multimedia content
• Personalization and content adaptation
• User interaction and relevance feedback
• Multimedia interfaces, presentation and visualization tools
Submission details
All the papers should be full journal length versions and follow the guidelines set out by Multimedia Tools and Applications: http://www.springer.com/journal/11042. Manuscripts should be submitted online at https://www.editorialmanager.com/mtap/choosing “CBMI 2014” as article type, no later than November 30th, 2014. When uploading your paper, please ensure that your manuscript is marked as being for this special issue. Information about the manuscript (title, full list of authors, corresponding author’s contact, abstract, and keywords) should also be sent to the corresponding editor Georges Quénot (Georges.Quenot@imag.fr). All the papers will be peer-reviewed following the MTAP reviewing procedures.
Important Dates (Tentative)
Submission of papers: November 30, 2014
Acceptance Notification: January 31, 2013
Submission of final manuscript: March 31, 2015
Publication of special issue: 2Q 2015
Guest Editors
Name: Dr. Georges Quénot Name: Dr. Harald Kosch
Email: Georges.Quenot@imag.f E-Mail: harald.kosch@uni-passau.de
Affiliation: CNRS-LIG Affiliation : University of Passau

Tuesday, November 18, 2014
MTAP Special Issue on Content Based Multimedia Indexing
Thursday, October 30, 2014
The top 100 papers

Article from Nature
The discovery of high-temperature superconductors, the determination of DNA’s double-helix structure, the first observations that the expansion of the Universe is accelerating — all of these breakthroughs won Nobel prizes and international acclaim. Yet none of the papers that announced them comes anywhere close to ranking among the 100 most highly cited papers of all time.
Citations, in which one paper refers to earlier works, are the standard means by which authors acknowledge the source of their methods, ideas and findings, and are often used as a rough measure of a paper’s importance. Fifty years ago, Eugene Garfield published the Science Citation Index (SCI), the first systematic effort to track citations in the scientific literature. To mark the anniversary, Nature asked Thomson Reuters, which now owns the SCI, to list the 100 most highly cited papers of all time. (See the full list at Web of Science Top 100.xls or the interactive graphic, below.) The search covered all of Thomson Reuter’s Web of Science, an online version of the SCI that also includes databases covering the social sciences, arts and humanities, conference proceedings and some books. It lists papers published from 1900 to the present day.
Read the entire article
Wednesday, October 22, 2014
Machine-Learning Maestro Michael Jordan on the Delusions of Big Data and Other Huge Engineering Efforts
Big-data boondoggles and brain-inspired chips are just two of the things we’re really getting wrong
The overeager adoption of big data is likely to result in catastrophes of analysis comparable to a national epidemic of collapsing bridges. Hardware designers creating chips based on the human brain are engaged in a faith-based undertaking likely to prove a fool’s errand. Despite recent claims to the contrary, we are no further along with computer vision than we were with physics when Isaac Newton sat under his apple tree.
Those may sound like the Luddite ravings of a crackpot who breached security at an IEEE conference. In fact, the opinions belong to IEEE Fellow Michael I. Jordan, Pehong Chen Distinguished Professor at the University of California, Berkeley. Jordan is one of the world’s most respected authorities on machine learning and an astute observer of the field. His CV would require its own massive database, and his standing in the field is such that he was chosen to write the introduction to the 2013 National Research Council report “Frontiers in Massive Data Analysis.” San Francisco writer Lee Gomes interviewed him for IEEE Spectrum on 3 October 2014.
Read the interview
Thursday, October 2, 2014
How Smart Are Smartphones?: Bridging the marketing and information technology gap.
My latest IEEE article (co-authored with A. Amanatiadis) is out. Please read the article and send me your comments!!
How Smart Are Smartphones?: Bridging the marketing and information technology gap.

The term "smart" has become widespread in consumer electronics in recent years, reflecting the consumers' need for devices that assist them in their daily activities. The term has a long history of usage in marketing science as one of the most appealing ways of promoting or advertising a product, brand, or service. However, even today, there is much controversy in the definition of this term and even more ambiguities for the right use in consumer electronic devices. Furthermore, it is not possible to carry out any quantitative or qualitative analysis of how smart a device is without having some adequate conception of what a smart or intelligent application means. This article attempts to explore the smart and intelligent capabilities of the current and next-generation consumer devices by investigating certain propositions and arguments along with the current trends and future directions in information technology (IT).
Sunday, September 28, 2014
Wednesday, August 27, 2014
Grire-example
This is an example implementation of Golden Retriever - an open source Image Retrieval Engine, located at grire.net
You may use this source for building a command line based image search engine.
Example command line arguments.
Adding an imagefolder
java -jar ajmg6.jar create ImagePoolName /home/username/YourGrireDb/db /home/username/YourImageFilesFolder 1f multi
Searching for an Image
java -jar ajmg6.jar search ImagePoolName /home/username/YourGrireDb/db /home/username/YourSourceFile.jpg
Tuesday, August 5, 2014
Click’n’Cut: Crowdsourced Interactive Segmentation with Object Candidates
Carlier A, Salvador A, Giró-i-Nieto X, Marques O, Charvillat V. Click’n’Cut: Crowdsourced Interactive Segmentation with Object Candidates. In: 3rd International ACM Workshop on Crowdsourcing for Multimedia (CrowdMM). In Press

Abstract
This paper introduces Click’n’Cut, a novel web tool for in- teractive object segmentation addressed to crowdsourcing tasks. Click’n’Cut combines bounding boxes and clicks gen- erated by workers to obtain accurate object segmentations. These segmentations are created by combining precomputed object candidates in a light computational fashion that al- lows an immediate response from the interface. Click’n’Cut has been tested with a crowdsourcing campaign to anno- tate a subset of the Berkeley Segmentation Dataset (BSDS). Results show competitive results with state of the art, es- pecially in time to converge to a high quality segmentation. The data collection campaign included golden standard tests to detect cheaters.
Tuesday, July 1, 2014
PhD position in computer vision and virtual currencies
Application deadline: Thu, 07/17/2014
Location:Girona, Spain
Employer:University of Girona & Social Currencies Management,SL
The University of Girona and the spin-off Social Currencies Management, SL are looking for a PhD candidate to investigate and develop algorithms on computer vision and social currencies, looking for new ways to monetize the visual content available on the social web.
We offer a three years PhD position with full time salary. This is a good opportunity to explore both, research at academic and industry level at the city of Girona (100km north from Barcelona).
The candidate should have a master degree on computer vision or similar and English proficiency. Experience on basic programming languages (matlab, C, C++, visual C etc.. ) and knowledge on artificial intelligence is also desired.
We are searching for a motivated PhD candidate with a background in machine learning to work on the areas of computer vision and multi-media (recognition, person dentification, attribute learning, weakly supervised learning), sentiment analysis, and internet/web data analytics.
Deadline: 17 July 2014
Start Date: October 2014
For further information please contact Anna Bosch (anna.easyinnova@gmail.com)
Project Description:
To date, the internet has been monetized primarily by text-based ads. In fact, an entire industry has developed around keyword optimization for ad buyers. Words drive SEO. Words drive Google and Facebook ads. Words drive economy of the web. However, it appears that Facebook will now be more show than tell. The shift to a personal newspaper-style format with larger and more prominent photo displays is a response to photo driven behaviour that has rapidly changed the social media landscape. In fact, Facebook CEO Mark Zuckerberg says that 50% of all posts are now pictures, double the amount from just a year ago. As we move toward a visual-centric content universe, the Machines that monetize the internet need to keep up with the times.
We wish to investigate on image intelligence; a way to systematically scan and detect the presence of brand logos, packaging, and products lurking inside the billions of consumer photos streaming into the internet each week; and a way to detect which are the most interesting images for the social users and that can be further used for branding. (According to Facebook, this social network alone gets more than 300 million photo uploads daily). A smart computer vision system applied to those photos could extract the relevant meta-data and essentially turn your friends’ pictures into buyable ad units. You click on the photo and are presented with targeted sales offers.
Project TangoOver the past 18 months, Projec
Over the past 18 months, Project Tango has been collaborating with robotics laboratories from around the world to concentrate the past decade of research and computer vision into a new class of mobile device.
Monday, May 19, 2014
HOW SMART ARE THE SMARTPHONES?

New Accepted Article:
A. Amanatiadis and S. A. Chatzichristofis, “HOW SMART ARE THE SMARTPHONES? BRIDGING THE MARKETING AND IT GAP”, «IEEE Consumer Electronics Magazine», IEEE, Accepted for Publication, 2014.
The term ``smart'' has become widespread in consumer electronics in recent years reflecting the need of consumers for devices that assist them in their daily activities. The term has a long history of usage in the marketing science as one of the most appealing ways of promoting or advertising a product, brand or service. However, even today, there is much controversy in the definition of this term and even more ambiguities for the right use in consumer electronic devices. Furthermore, it is not possible to carry out any quantitative or qualitative analysis of how smart a device is, without having some adequate conception of what a smart or intelligent application means. This article can be viewed as an attempt to explore the smart and intelligent capabilities of the current and next generation consumer devices by investigating certain propositions and arguments along with the current trends and future directions in information technology.
(I’ll add some more details about the article in few days)
Wednesday, May 14, 2014
Pacific-Rim Conference on Multimedia (PCM) 2014
Dec. 1-4, 2014, Kuching, Sarawak, Malaysia
The Pacific-Rim Conference on Multimedia (PCM) is the major annual international conference in Asia organized as a forum for the dissemination of state-of-the-art technological advances and research results in the fields of theoretical, experimental, and applied multimedia analysis and processing. The conference calls for research papers reporting original investigation results and industrial-track papers reporting real-world multimedia applications and system development experiences. The conference also solicits proposals for tutorials on enabling multimedia technologies, and calls for dedicated special session proposals focusing on emerging challenges in the multimedia arena.
AN UNFORGETTABLE EXPERIENCE
===========================
PCM 2014 will be held in Kuching, Sarawak, Malaysia. Sarawak, also known as the "Land of the Hornbills", offers an unforgettable mix of culture- and nature-based travel experiences. Tourists can indulge themselves in a wide range of attractions including enjoying the charms of historic Kuching, a beautiful waterfront city; exploring the massive cave systems of Mulu National Park; jungle trekking and wildlife watching at Bako National Park; traveling upriver to visit the Iban and experience longhouse life.
TOPICS OF INTERESTS
===================
PCM 2014 is seeking high quality submissions in the broad field of multimedia.
The topics of interests include, but are not limited to, the following:
- Multimedia analysis, indexing, and retrieval
- Multimedia security and rights management
- Multimedia coding, compression, and processing
- Multimedia communication and networking
- Multimedia systems, tools, services, and applications
We welcome submissions on the above topics in the following context:
- Social networks and social media
- Cloud computing
- Big data analytics
- Crowdsourcing
- Mobile and wearable computing
- Multimedia sensing
- 3D and multi-view computing
CALL FOR WORKSHOP PROPOSALS
===========================
PCM Workshop Co-Chairs are seeking for organizers of workshops at PCM 2014 and invite active members of the community to submit proposals. The selected workshops should address specialized topics which are relevant for researchers and practitioners working in the field of multimedia. Emerging research themes that attract interest of the community are preferred.
Workshop proposals that include ideas to initiate lively discussions and interactions are also welcome.
Submissions should be mailed to the Workshop Co-Chairs, including the
following details:
- Title
- Abstract
- Relevance and significance of this workshop to the main conference
- Length - Full day or half day
- A draft workshop call for papers
- The names, affiliations, email addresses and short bio of the
workshop organizers
- A list of potential Program Committee members and their affiliations
(submission should not exceed 4 pages, including CFP)
Workshop proposals will be reviewed by PCM 2014 Workshop Co-Chairs based on these criteria: a) the likely interest of the workshop to PCM attendees, b) originality, breadth and depth of the topic, c) the expertise and credential of the organizer(s)
IMPORTANT DATES:
Proposal Submission Deadline: 31 May 2014
Proposal Acceptance: 20 June 2014
Workshop Paper Submission Deadline: to be announced
Workshop Camera Ready: to be announced
Workshop Day: 1st of December 2014
Workshop Co-chairs:
Liang-Tien Chia, Clement (Nanyang Technological University, Singapore), E-Mail: asltchia <AT> ntu.edu.sg
Ralph Ewerth (Jena University of Applied Sciences, Germany), E-Mail: Ralph.Ewerth <AT> fh-jena.de
CALL FOR SPECIAL SESSION PROPOSALS
==================================
Special sessions supplement the regular program for PCM 2014. They are intended to cover new and emerging topics in the fields of multimedia. Each special session should provide an overview of the state of the arts and highlight important research directions in a field of special interest to PCM participants. It should be a focused effort rather than defined broadly.
Each special session should consist of at least 5 oral papers. It is encouraged that the session begins with an overview paper on the topic being addressed and that the remaining papers follow up with technical contributions on the topic.
The following information should be included in the proposal:
- Title of the proposed special session
- Names and affiliations of the organizers (including bios and contact info)
- Session abstract
- List of authors committed to submit paper (including a tentative title
and a 300-word abstract for each paper)
The session abstract should answer the following three questions:
- Motivation: why is this topic important for organizing a special session
in PCM14?
- Objective: who will be interested to submit papers?
- Target audience and key message: what can the attendees learn from this
special session?
This is a competitive call. Proposals will be evaluated based on the timeliness of the topic and relevance to PCM, as well as the qualification of the organizers and quality of papers in the proposed session.
IMPORTANT DATES:
Special Session Proposal Due: 31 May 2014
Notification of Proposal Acceptance: 10 June 2014
Special Session Paper Submission: 10 July 2014
Notification of Paper Acceptance: 10 August 2014
Camera-Ready Paper Due: 31 August 2014
Please email proposal to Lexing Xie (lexing.xie{at}anu.edu.au) and Jianfei Cai (asjfcai{at}ntu.edu.sg)
CALL FOR TUTORIALS
==================
The conference also solicits proposals for tutorials on enabling multimedia technologies including the topics of the conference (details on the website):
- Multimedia Content Analysis
- Multimedia Signal Processing and Communications
- Multimedia Applications and Services
- Emerging Topics
SUBMISSION:
Please directly submit your tutorial proposal to:
Winston Hsu (whsu [AT] ntu.edu.tw)
Roger Zimmermann (rogerz [AT] comp.nus.edu.sg)
IMPORTANT DATES:
Tutorial Proposal Submission: 31 May 2014
Acceptance notification: 20 June 2014
CALL FOR CONFERENCE PAPERS
==========================
PCM 2014 accepts both full, short and demo papers. Full papers will be presented in the format of either oral or poster, while short papers will be presented in the format of poster. There will be awards for full, short and demo papers. We will not accept any paper which, at the time of submission, is under review or has already been published or accepted for publication in a journal or another conference. Papers should be formatted according to the Lecture Notes in Computer Science template available at the PCM2014 website. A full paper should be 9-10 pages in length; short papers should be exactly 6 pages, and demo paper should be exactly 4 pages. The Proceedings of PCM2014 will be published in a book series of Lecture Notes in Computer Science by Springer. Papers should be submitted electronically in PDF via EasyChair:
https://www.easychair.org/conferences/?conf=pcm2014
31 May 2014: Regular paper submission
15 June 2014: Demo paper submission
10 Aug 2014: Notification of acceptance
31 Aug 2014: Camera ready submission
MORE INFORMATION
================
http://conference.cs.cityu.edu.hk/pcm2014/
New Datasets
The Fish4Knowledge project (groups.inf.ed.ac.uk/f4k/) is pleased to announce the availability of 2 subsets of our tropical coral reef fish video and extracted fish data. See below for 3 other
Fish4Knowledge project datasets.
Dataset #1: a 10 minute video clip from all working cameras taken at 08:00 every day in the project Oct 1, 2010 - July 10, 2013, giving 5824 video clips (of 7-30 Mb). Note, some dates are missing. This data allows analysis of fish patterns over annual cycles and comparison between sites. About 2.5 M fish were detected.
Dataset #2: 690 10 minute video clips from the 9 cameras taken from 06:00 - 19:00 on April 22, 2011 (out of 702 possible). This data allows analysis of fish patterns over a full day period and comparison between sites. About 16 M fish were detected.
For each 10 minute video clip, there is also a CSV file that describes all fish ( of a sufficient size) that were detected in the video, including a boundary and a species identification.
There were up to 24 species recognized.
You might find the datasets useful for target detection in a tough undersea environment, multi-class recognition (where there are many false detections and mis-classifications), or even a bit of ecological analysis.
You can find the data at:
http://groups.inf.ed.ac.uk/f4k/F4KDATASAMPLES/INTERFACE/DATASAMPLES/search.php
Use of the data should include this citation:
Bastiaan J. Boom, Jiyin He, Simone Palazzo, Phoenix X. Huang, Hsiu-Mei Chou, Fang-Pang Lin, Concetto Spampinato, Robert B. Fisher; A research tool for long-term and continuous analysis of fish assemblage in coral-reefs using underwater camera footage Ecological Informatics, 2014, DOI: dx.doi.org/10.1016/j.ecoinf.2013.10.006.
Tuesday, May 13, 2014
Making Video Interaction on Touch Devices Consistent
Article from http://vidosearch.com/
 The video players on smartphones and tablets typically use seeker-bars for temporal navigation in videos. In order to jump to different positions in the video you simply have to drag the seeker-bar. However, we argue that this interaction concept is inconsistent to usual interaction with other media on touch devices. For example, in a photo collection you perform horizontal wipe (i.e., drag) gestures in order to browse through all photos of the collection. Similarly, when scrolling through documents or presentation slides, you perform horizontal (or vertical) wipe gestures. Hence, we propose to use such wipe gestures also for navigation in video. Our work combines the ideas proposed earlier by Huber et al. and Hürst et al. in order to allow flexible navigation within a single video but also in a video collection. More details can be found in the preprint of our paper “Video Navigation on Tablets with Multi-Touch Gestures”, to be presented at the 3rd International Workshop on Emerging Multimedia Systems and Applications (EMSA) at the IEEE International Conference on Multimedia & Expo (ICME) in July 2014 in Chengdu, China. Ourprototype is also available on the App Store on iTunes for the Apple iPad (many thanks to Kevin Chromik for the implementation and evaluation)!
The video players on smartphones and tablets typically use seeker-bars for temporal navigation in videos. In order to jump to different positions in the video you simply have to drag the seeker-bar. However, we argue that this interaction concept is inconsistent to usual interaction with other media on touch devices. For example, in a photo collection you perform horizontal wipe (i.e., drag) gestures in order to browse through all photos of the collection. Similarly, when scrolling through documents or presentation slides, you perform horizontal (or vertical) wipe gestures. Hence, we propose to use such wipe gestures also for navigation in video. Our work combines the ideas proposed earlier by Huber et al. and Hürst et al. in order to allow flexible navigation within a single video but also in a video collection. More details can be found in the preprint of our paper “Video Navigation on Tablets with Multi-Touch Gestures”, to be presented at the 3rd International Workshop on Emerging Multimedia Systems and Applications (EMSA) at the IEEE International Conference on Multimedia & Expo (ICME) in July 2014 in Chengdu, China. Ourprototype is also available on the App Store on iTunes for the Apple iPad (many thanks to Kevin Chromik for the implementation and evaluation)!
Article from http://vidosearch.com/
Thursday, May 1, 2014
Avidbots Wants to Automate Commercial Cleaning With Robots

Vacuuming is one of the few markets where robots have proven that they can be consistently commercially successful. There's a good reason for this: vacuuming is a repetitive, time-intensive task that has to be performed over and over again in environments that are relatively constrained. Despite the success of several companies in the home robot vacuum space, we haven't seen many low cost platforms designed for commercial areas, but a startup called Avidbots is tackling this idea, and they've got operational prototypes.
The problem that these robots are really going to have to solve is the same problem that the Roomba struggles with: cleaning robots are not a substitute for a cleaning human. A Roomba (to use a recognizable example) is amaintenance tool, designed to keep your floors cleaner, longer. But, no matter how often you use your Roomba, you'll still need to occasionally bust out the upright vacuum yourself. It'll be far lass often than you would without a Roomba, but it'll still need to happen, because humans can visually identify dirt and manually maneuver cleaning equipment into places that robots can't reach.
In the case of the Avidbots, you can see in the demo that despite their care with edging, they still miss some areas in corners, close to walls, near complex obstacles, underneath objects that should be temporarily moved, and so forth. Over time, those areas are going to get super dirty, and you'll need to bring in a human to clean them. You'll also have to have humans around to maintain the robots, cleaning them out, replacing fluids, and charging them if they don't auto dock. You'll certainly spend way less human time and labor on cleaning (which is the point, of course), but we're not yet at the point where we can just leave robots completely on their own to perform tasks in human environments.
Wednesday, April 30, 2014
Google's Autonomous Cars Are Smarter Than Ever at 700,000 Miles

Google has just posted an update on its self-driving car program, which we've been watching closely for the past several years. The cars have surpassed 700,000 autonomous accident-free miles (around 1.13 million kilometers), and they're learning how to safely navigate through the complex urban jungle of city streets. Soon enough, they'll be better at it than we are. Much better.
We’ve improved our software so it can detect hundreds of distinct objects simultaneously—pedestrians, buses, a stop sign held up by a crossing guard, or a cyclist making gestures that indicate a possible turn. A self-driving vehicle can pay attention to all of these things in a way that a human physically can’t—and it never gets tired or distracted.
This is why we're so excited about a future full of autonomous cars. Yes, driving sucks, especially in traffic, and we'd all love to just take a nap while our cars autonomously take us wherever we want to go. But the most important fact is that humans are just terrible at driving. We get tired and distracted, but that's just scratching the surface. We're terrible at dealing with unexpected situations, our reaction times are abysmally slow, and we generally have zero experience with active accident avoidance if it involves anything besides stomping on the brakes and swerving wildly, which sometimes only make things worse.
An autonomous car, on the other hand, is capable of ingesting massive amounts of data in a very short amount of time, exploring multiple scenarios, and perhaps even running simulations before it makes a decision designed to be as safe as possible. And that decision might (eventually) be one that only the most skilled human driver would be comfortable with, because the car will know how to safely drive itself up to (but not beyond) its own physical limitations. This is a concept that Stanford University was exploring before most of that team moved over to Google's car program along with Sebastian Thrun.

Now, I may be making something out of nothing here, but if we compare the car in the image that Google provided with its latest blog post withan earlier Google car from 2012 (or even the Google car in the video), you'll notice that there's an extra piece of hardware mounted directly underneath the Velodyne LIDAR sensor: a polygonal black box (see close-up, right). I have no idea what'sin that box, but were I to wildly speculate, my guess would be some sort of camera system with a 360-degree field of view.
The Velodyne LIDAR is great at detecting obstacles, but what Google is working on now is teaching their cars to understand what's going on in their environment, and for that, you need vision. The cars always had cameras in the front to look for road signs and traffic lights, but detecting something like a cyclist making a hand signal as they blow past you from behind seems like it would require fairly robust vision hardware along with some fast and powerful image analysis software.
Or, it could be radar. Or more lasers. We're not sure, except to say that it's new(ish), and that vision is presumably becoming more important for Google as they ask their cars to deal with more complex situations with more variables.
Wednesday, April 23, 2014
Project Naptha
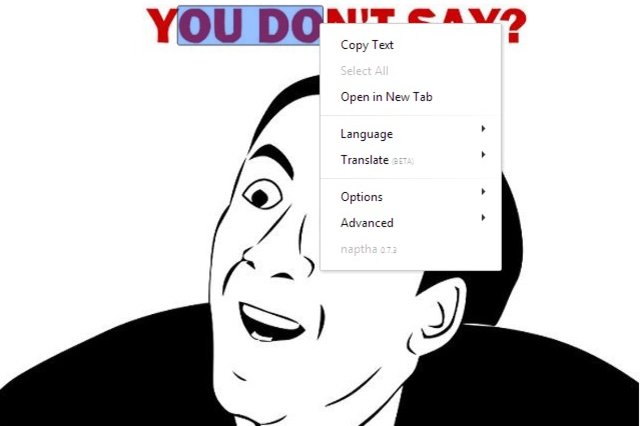
Meme generation might never be the same again. Project Naptha is a browser extension that lets users select, copy, edit and translate text from any image — so long as it is under 30 degrees of rotation. The plug-in runs on the Stroke Width Transform algorithm Microsoft Research invented for text detection in natural scenes. It also provides the option of using Google's open-source OCR engine Tesseract when necessary. Project Naptha utilizes a technique called "inpainting" to reconstruct images after they've been altered by the extension. According to the website, this entails using an algorithm that fills in the space previously occupied by text with colors from the surrounding area. Right now, the program is only compatible with Google Chrome but a Firefox version may be released in a few weeks.
http://www.theverge.com/2014/4/23/5642144/easy-meme-editing-with-project-naptha-browser-plugin
Sunday, April 6, 2014
SIMPLE Descriptors
Abstract: In this paper we propose and evaluate a new technique that localizes the description ability of several global descriptors. We employ the SURF detector to define salient image patches of blob-like textures and use the MPEG-7 Scalable Color (SC), Color Layout (CL), Edge Histogram (EH) and the Color and Edge Directivity Descriptor (CEDD) descriptors to produce the final local features’ vectors named SIMPLE-SC, SIMPLE-CL, SIMPLE-EH and SIMPLE-CEDD or “LoCATe” respectively. In order to test the new descriptors in the most straightforward fashion, we use the Bag-Of-Visual-Words framework for indexing and retrieval. The experimental results conducted on two different benchmark databases, with varying codebook sizes revealed an astonishing boost in the retrieval performance of the proposed descriptors compared both to their own performance (in their original form) and to other state-of-the-art methods of local and global descriptors.
A set of local image descriptors specifically designed for image retrieval tasks
Image retrieval problems were first confronted with algorithms that tried to extract the visual properties of a depiction in a global manner, following the human instinct of evaluating an image’s content. Experimenting with retrieval systems and evaluating their results, especially on verbose images and images where objects appear with partial occlusions, showed that the accepted correctly ranked results are positively evaluated by the extraction of the salient regions of an image, rather than the overall depiction. Thus, a representation of the image by its points of interest proved to be a more robust solution. SIMPLE descriptors, emphasize and incorporate the characteristics that allow a more abstract but retrieval friendly description of the image’s salient patches.
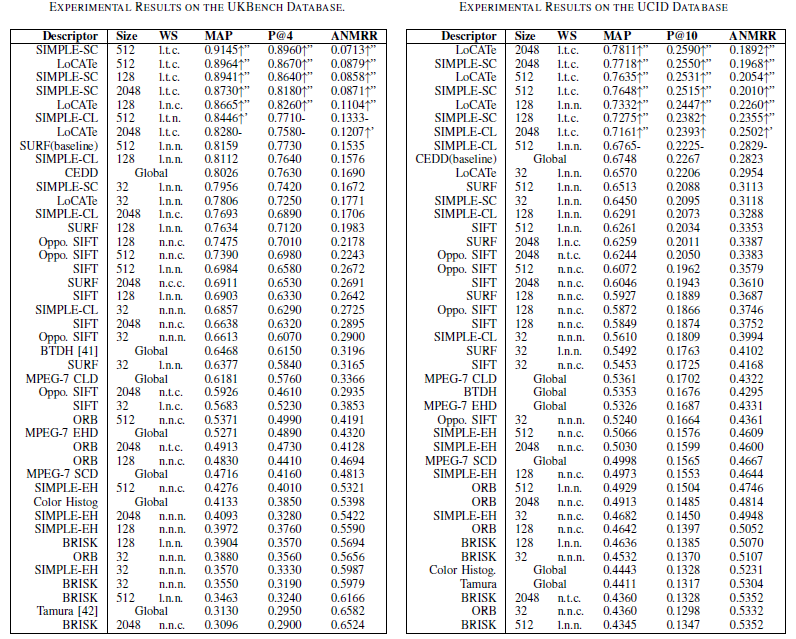
Experiments were contacted on two well-known benchmarking databases. Initially experiments were performed using the UKBench database. The UKBench image database consists of 10200 images, separated in 2250 groups of four images each. Each group includes images of a single object captured from different viewpoints and lighting conditions. The first image of every object is used as a query image. In order to evaluate our approach, the first 250 query images were selected. The searching procedure was executed throughout the 10200 images. Since each ground truth includes only four images, the P@4 evaluation method to evaluate the early positions was used.
In the sequel, experiments were performed using the UCID database. This database consists of 1338 images on a variety of topics including natural scenes and man-made objects, both indoors and outdoors. All the UCID images were subjected to manual relevance assessments against 262 selected images.
In the tables that illustrate the results, wherever the BOVW model is employed, only the best result achieved by each descriptor with every codebook size, is presented. In other words, for each local feature and for each codebook size, the experiment was repeated for all 8 weighting schemes but only the best result is listed in the tables. Next to the result, the weighting scheme for which the result was achieved is noted (using the System for the Mechanical Analysis and Retrieval of Text – SMART notation)
Source Code and more details are available at http://chatzichristofis.info/?page_id=1479
Details regarding these descriptors can be found at the following paper: (in other words, if you use these descriptors in your scientific work, we kindly ask you to cite the following paper )
C. Iakovidou, N. Anagnostopoulos, Y. Boutalis, A. Ch. Kapoutsis and S. A. Chatzichristofis, “SEARCHING IMAGES WITH MPEG-7 (& MPEG-7 Like) POWERED LOCALIZED DESCRIPTORS: THE SIMPLE ANSWER TO EFFECTIVE CONTENT BASED IMAGE RETRIEVAL”, «12th International Content Based Multimedia Indexing Workshop», June 18-20 2014, Klagenfurt – Austria (Accepted for Publication)
Thursday, March 27, 2014
RoboWow: A Home Robot That Does Everything?

Today is not April 1. I mention this because you should consider the following video in an April 1st context. That is to say, what you are about to see is notreal.
The only robot that can vacuum your home, clean your pool and mow your lawn!
It's no secret that creating Robowow proved to be just a bit of a challenge. After all, it's not every day you create a robot that can do almost everything but make the coffee.
From carpet challenges to pool-side shenanigans and minor mowing misdemeanors, we certainly had our work cut out for us! But, in true Robomow style, with a lot of perseverance and a little luck, we went ahead to create the most advanced, domesticated robot ever made.
Now, all that's left is for you to sit back and relax while Robowow... Does it all for you.
Obviously, the folks at Robomow who had this commercial made have a sense of humor.
But the question that it poses is real: what's the future of robots in our homes, anyway? Like, having a single robot that can do a whole bunch of tasks soundslike a great idea, but is it practical?
Let's take a very simple example: a robot vacuum that can climb stairs. In the above video, the RoboWow deals with stairs by, um, hovering? But people have been working on ways of getting robots to climb stairs for a long, long time, because it seems like it's something a domestic robot really should know how to do: if you had a robot that could climb stairs, it could clean houses that are more than one floor, and that would be awesome.
Realistically, however, the solution to multiple floors is far simpler than climbing stairs: just get one robot per floor. It's not clever, but at present, it's probably the best (or at least, most efficient) way to do it. The same goes for robots that mow lawns, clean pools, and so forth: focused robots that can be optimized for single, relatively simple tasks are likely to be much better at what they do while also being much cheaper to buy.
The way to get a household robot that can accomplish multiple tasks is to give it the ability to use the same tools that a human uses. When a robot can use a vacuum or push a lawn mower, then you've got something that can complete a variety of tasks, but we're pretty far from a system like that. You're looking at perhaps a PR2 or a UBR-1, with a lot of fancy programming that doesn't exist yet.
I'd love to be able to tell you that we're close to something like a RoboWow, because I desperately want one. But for the near future, unitasking household robots are going to be the way to go.
Article from http://spectrum.ieee.org/automaton/robotics/home-robots/robowow-robot-does-everything
Image Retrieval in Remote Sensing
Deadline is approaching…
The proliferation of earth observation satellites, together with their continuously increasing performances, provides today a massive amount of geospatial data. Analysis and exploration of such data leads to various applications, from agricultural monitoring to crisis management and global security.
However, they also raise very challenging problems, e.g. dealing with extremely large and real time geospatial data, or user-friendly querying and retrieval satellite images or mosaics. The purpose of this special session is to address these challenges, and to allow researchers from multimedia retrieval and remote sensing to meet and share their experiences in order to build the remote sensing retrieval systems of tomorrow.
Topics of interest
- Content- and context-based indexing, search and retrieval of RS data
- Search and browsing on RS Web repositories to face the Peta/Zettabyte scale
- Advanced descriptors and similarity metrics dedicated to RS data
- Usage of knowledge and semantic information for retrieval in RS
- Maching learning for image retrieval in remote sensing
- Query models, paradigms, and languages dedicated to RS
- Multimodal / multi-obsevations (sensors, dates, resolutions) analysis of RS data
- HCI issues in RS retrieval and browsing
- Evaluation of RS retrieval systems
- High performance indexing algorithms for RS data
- Summarization and visualization of very large satellite image datasets
- Applications of image retrieval in remote sensing
Many public datasets are available to researchers and can be used to evaluate the contributions related to image retrieval in remote sensing. The UC Merced Land Use Dataset is of particular interest in this context, with 2100 RGB images, 21 classes (http://vision.ucmerced.edu/datasets/landuse.html).
Important dates
- Submission deadline: April, 7th
- Notification to authors: May, 12th
- Camera-ready deadline: May, 20th
Contact
For more information please contact the special session chairs Sébastien Lefèvre (sebastien.lefevre <at> irisa.fr) and Philippe-Henri Gosselin (gosselin <at> ensea.fr)
http://cbmi2014.itec.aau.at/image-retrieval-in-remote-sensing/
PostDoc position (3 years) at Alpen-Adria Universität Klagenfurt, Austria
Institute of Information Technology, Multimedia Communication (MMC) Group (Prof. Hermann Hellwagner)
The MMC group at Klagenfurt University, Austria, is offering a full, three-year PostDoc position (available now) in a basic research project called CONCERT (http://www.concert-project.org/). Important facts about the project are given in the following. We seek candidates with strong expertise in one or several of the following areas: Multimedia Communication, Machine Learning, Multi-Agent Systems, Uncertainty in Artificial Intelligence (Probabilistic Models, Bayesian Networks, Game Theory). Applications should be sent to Prof. Hermann Hellwagner <hermann.hellwagner@aau.at>.
Title: A Context-Adaptive Content Ecosystem Under Uncertainty (CONCERT)
Duration: 3 years
Website: http://www.concert-project.org/
Partners
- University College London (UK): Prof. George Pavlou, Dr. Wei Chai (Coordinator)
- University of Surrey (UK): Dr. Ning Wang
- Ecole Polytechnique Fédérale de Lausanne (CH): Prof. Pascal Frossard
- Alpen-Adria-Universität (AAU) Klagenfurt (AT): Prof. Hermann Hellwagner
Project character and funding
CONCERT is an international basic research project accepted as a CHIST-ERA project under the Call for Proposals “Context- and Content-Adaptive Communication Networks”. CHIST-ERA is an ERANET consortium, part of the EC FP7 Programme “Future and Emerging Technologies (FET)” (http://www.chistera.eu/). Funding is provided by the national basic research funding agencies, in Austria the FWF (Austrian Science Fund).
Abstract
The objective of CONCERT is to develop a content ecosystem encompassing all rele- vant players which will be able to perform intelligent content and network adaptation in highly dynamic conditions under uncertainty. This ecosystem will have as basis emerging information-/content-centric networking technologies which support in- trinsic in-network content manipulation. The project will consider uncertainty aspects in the following two application domains: (1) social media networks based on user generated content and (2) CDN-like professional content distribution (Content Distri- bution Networks). Three dimensions of uncertainties will be addressed: (1) heteroge- neous and changing service requirements by end users, (2) threats that may have adverse impacts on the content ecosystem, as well as (3) opportunities that can be exploited by specific players in order to have their costs reduced …
Switzerland to host the first Cybathlon, an Olympics for bionic athletes
Article from http://www.theverge.com/2014/3/26/5551180/switzerland-to-host-the-first-cybathlon-an-olympics-for-bionic

A coalition of Swiss robotics labs has announced the Cybathlon, the first-ever international competition for athletes who use prosthetics and other aids, will be held in October of 2016.
The competition is modeled after the Olympics and will feature six events: a bike race, leg race, wheelchair race, exoskeleton race, arm prosthetics race, and Brain Computer Interface race for competitors with full paralysis. The National Centre of Competence in Research (NCCR) Robotics is hosting the competition to spur interest in emerging human-oriented robotics technologies.
Unlike the Olympics, where athletes can use prosthetics only to make themselves as good as able-bodied athletes and not better, Cybathlon competitors are encouraged to use the best technology. Dual prizes will be awarded, one to the athlete and one to the company that created the prosthetic, device, or software.
"The rules of the competition are made in such way that the novel technology will give the pilot an advantage over a pilot that would use a comparable but less advanced or conventional assistive technology," the organization says on its website. "There will be as few technical constraints as possible, in order to encourage the device providers to develop novel and powerful solutions."
Of course, the races will be slower than their Olympic counterparts, but they're also arguably more mind-boggling. The exoskeleton competitors, for example, must walk over a slope, up steps, around pillars, over a see-saw, across a narrow beam, then pick up a bag and carry it, go around tight corners, and then sprint to the finish line.
Tuesday, March 18, 2014
Facebook’s DeepFace Project Nears Human Accuracy In Identifying Faces
Article from: http://techcrunch.com/2014/03/18/faceook-deepface-facial-recognition/
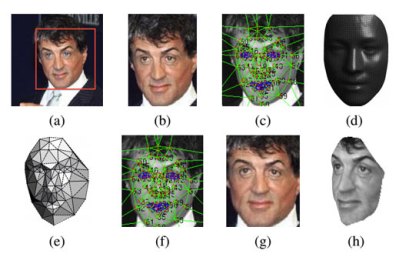
Facebook has reached a major milestone in computer vision and pattern recognition, with ‘DeepFace,’ an algorithm capable of identifying a face in a crowd with 97.25 percent accuracy, which is pretty much on par with how good the average human is (97.5 percent accurate) at recognizing the faces of other walking, talking meat sacks.
To get past the limitations of ordinary facial matching software, Facebook’s researchers have managed to find a way to build 3D models of faces from a photo, which can then be rotated to provide matching of the same face captured at different angles. In the past, facial recognition via computer could be pretty easily foiled if a subject is simply tilting their head in a slightly different direction.
The Facebook DeepFace algorithm needs to be trained on an extensive pool of faces to be able to perform its magic, but it can identify up to 4,000 identities based on a database of over 4 million separate images in its current version. Theoretically, that could be expanded to cover a much larger swatch with further work, and then be applied to Facebook’s social network itself, which would be very useful if Facebook wanted to automate the process of identifying all your contacts, and performing analytical magic like determining who you’re photographed most frequently with, without the use of manual tagging.
So far, this project is being put forward as mostly an academic pursuit,in a research paper released last week, and the research team behind it will present its findings at the Computer Vision and Pattern Recognition conference in Columbus, Ohio in June. Still, it has tremendous potential for future application, both for Facebook itself and in terms of its ramifications for the field of study as a whole.
Article from: http://techcrunch.com/2014/03/18/faceook-deepface-facial-recognition/
6th International Conference on Social Informatics
The International Conference on Social Informatics (SocInfo) is an interdisciplinary venue that brings together researchers from informatics and social sciences to help fill the gap between the two communities. The goal of the conference is to contribute to the definition and exploration of common methodologies and research goals that encompass the objectives and motivate the two disciplines. The venue welcomes contributions on methods from the social sciences applied to the study of socio-technological systems but also about the application of information technology to the study of complex social processes, and the use of social concepts in the design of information systems.
The conference creates an opportunity for the dissemination of knowledge between the two communities by soliciting presentations of original research papers and experience-based case studies in computer science, sociology, psychology, political science, anthropology, economics, linguistics, artificial intelligence, social network analysis, and other disciplines that can shed light on the open questions in the growing field of computational social science.
The event will also offer tutorials, workshops and keynote talks that will be tailored to address the collaboration between the two research cultures in an era when social interactions are ubiquitous and span offline, online and augmented reality worlds.
Research topics of interest include, but are not limited to:
- New theories, methods and objectives in computational social science
- Computational models of social phenomena and social simulation
- Social behavior modeling
- Social communities: discovery, evolution, analysis, and applications
- Dynamics of social collaborative systems
- Social network analysis and mining
- Mining social big data
- Social Influence and social contagion
- Web mining and its social interpretations
- Quantifying offline phenomena through online data
- Rich representations of social ties
- Security, privacy, trust, reputation, and incentive issues
- Opinion mining and social media analytics
- Credibility of online content
- Algorithms and protocols inspired by human societies
- Mechanisms for providing fairness in information systems
- Social choice mechanisms in the e-society
- Social applications of the semantic Web
- Social system design and architectures
- Virtual communities (e.g., open-source, multiplayer gaming, etc.)
- Impact of technology on socio-economic, security, defense aspects
- Real-time analysis or visualization of social phenomena and social graphs
- Socio-economic systems and applications
- Collective intelligence and social cognition
Original manuscripts should be submitted in English in pdf format to the EasyChair submission system (https://www.easychair.org/conferences/?conf=socinfo2014). They should be formatted according to Springer LNCS paper formatting guidelines (http://www.springer.com/computer/lncs?SGWID=0-164-6-793341-0). The length of the full papers should not exceed 14 pages (excluding references).
As in the previous years, the accepted papers will appear in Springer’s Lecture Note Series in Computer Science but we also allow accepted papers to be presented without publication in the conference proceedings, if the authors choose to do so. Some of the full paper submissions can be accepted as short papers based on the decision of the Program Committee. Best papers will be selected and invited for extended journal publications.
To ensure a thorough and fair review process, this year’s conference will rely on a two-tier review process and will enforce strict review guidelines to provide even higher-quality feedback to authors. To further incentivate good feedback to authors, contributions of best reviewers will be awarded with special mentions.
Important dates
- Full paper submission: August 8, 2014 (23:59 Hawaii Standard Time)
- Notification of acceptance: September 19, 2014
- Submission of final version: October 10, 2014
- Conference dates: November 10-13, 2014
Used-Car-Style Marketing Comes to Scholarly Publishing
Article from http://scholarlyoa.com/2014/02/26/used-car-style-marketing-comes-to-scholarly-publishing/

Not the way it’s supposed to work.
We recently learned of a website called PublishFast® that offers to sell quick and easy publishing opportunities for scholarly authors.
The site calls itself a “confidential academic service” and says it will help you “get a VIP treatment from the editors of a selection of top-quality journals which are indexed by Science Citation Index (SCI)*, Social Sciences Citation Index (SSCI)*, Arts and Humanities Citation Index (AHCI)* and Scopus*.”
The journal titles are not divulged on the site. The company also boasts, “PublishFast® is probably the best kept secret among many proliferate researchers in the academic world for years!” [I think they mean prolific, not proliferate].
This statement — plus a chart on the main page — misleads readers into believing that the service started in 2011. In fact, the domain-name registration data suggests a recent UK origin:
Registrant’s address:
First Avenue
Publishers Bldg
Bodmin
CON
PL31 2JX
United Kingdom
Registrar
1 & 1 Internet AG [Tag = SCHLUND]
URL: http://www.1and1.co.uk or http://registrar.1und1.info
Relevant dates:
Registered on: 17-Feb-2014
Expiry date: 17-Feb-2016
Last updated: 17-Feb-2014
Regarding cost, on its FAQ page, PublishFast says it charges $199. But this charge is just for the service. There is likely a separate fee for the APC, the article processing charge, once the paper gets accepted.
I am certain that everyone with a stake in the future of scholarly communication will agree that this site is a corruption of the ideals of scholarship. Let’s all hope it goes away soon.
Article from http://scholarlyoa.com/2014/02/26/used-car-style-marketing-comes-to-scholarly-publishing/
IST2014
Following the success of events in Stresa, Italy 2004, Niagara Falls in Canada 2005, Minori in Italy 2006, Krakow in Poland 2007, Chania in Greece 2008, Shenzhen in China 2009, Thessaloniki in Greece 2010 Penang in Malaysia 2011, Manchester in the UK 2012, and the recent success in Beijing in China 2013, the 2014 IEEE International Conference on Imaging Systems and Techniques (IST 2014) and the IEEE International School of Imaging (ISI) will take place in Santorini Island, Greece.
Engineers, scientists and medical professionals from Industry, Government, Academia, and Medical Laboratories who want to maximize their technical and clinical skills in challenging areas and emerging frontiers of imaging and diagnostic device industry, can attend the IST Conference and the School (ISI) and interact with major worldwide experts.
The IST 2014 Conference and the International School of Imaging are two distinct events, taking place consecutively, and both addressing the following four areas:
MEDICAL DIAGNOSTICS AND THERANOSTICS
- Clinical diagnostics and theranostics devices and techniques
- Miniaturization of diagnostic devices and mass spectroscopy systems
- Electroluminescence, bioluminescence, and amplification fluorescence
- Biomarkers, proteomics, Imaging genomics, sequencing, and microfluidic chips
- Nanoscale materials, polymer nanostructures, nanophotonics, and nanomedicine
- Image processing and pattern recognition
SPACE DEFENSE
- Defense and space surveillance imaging technologies
- Advanced space instruments and satellite imaging
- Multilayered imaging technologies
- Bioinspired Imaging, robotics, guidance and control
- Image processing and pattern recognition
MATERIAL INSPECTION AND MANUFACTURING
- Semiconductor wafers, nanomaterials, composites, and corrosion
- Sensors and image acquisition
- Illumination architectures
- In-line inspection rapid, whole wafer defect detection
- Off-line inspection for defect review and failure analysis
- Techniques for critical dimension (CD) and overlay metrology
- Automatic defect classification
- Pharmaceutical and food processing vision Inspection Systems
- Image processing and pattern recognition
IMAGING MODALITIES
- Cameras, microscopy and displays
- Polarimetry, multispectral imaging
- Tomography (CT, SPECT, PET, ECT)
- Ultrasound and laser acoustics
- Multimodality Imaging
- Energy harvesting and imaging technologies
- Emerging imaging trends
Saturday, March 15, 2014
Thursday, March 13, 2014
VISION-CONTROLLED MICRO FLYING ROBOTS: FROM SYSTEM DESIGN TO AUTONOMOUS NAVIGATION AND MAPPING IN GPS-DENIED ENVIRONMENTS
Great News: Our paper “VISION-CONTROLLED MICRO FLYING ROBOTS: FROM SYSTEM DESIGN TO AUTONOMOUS NAVIGATION AND MAPPING IN GPS-DENIED ENVIRONMENTS” has just been accepted at IEEE Robotics and Automation Magazine.
To the best of our knowledge, this paper describes the first, working visual-inertial system of multiple MAVs in real-world scenarios able to autonomously navigate while collaboratively building a rich 3D map of the environment and performing optimal surveillance coverage. It is believed that the presented system constitutes a milestone for vision based MAV navigation in large, unknown, and GPS-denied environments, providing a reliable basis for further research towards complete missions of search-and-rescue or inspection scenarios with multiple MAVs.

D. Scaramuzza, M.C. Achtelik, L. Doitsidis, F. Fraundorfer, E.B. Kosmatopoulos, A. Martinelli, M.W. Achtelik, M. Chli, S. A. Chatzichristofis, L. Kneip, D. Gurdan, L. Heng, G.H. Lee, S. Lynen, L. Meier, M. Pollefeys, A. Renzaglia, Roland Siegwart, J.C. Stumpf, P. Tanskanen, C. Troiani and S. Weiss, “VISION-CONTROLLED MICRO FLYING ROBOTS: FROM SYSTEM DESIGN TO AUTONOMOUS NAVIGATION AND MAPPING IN GPS-DENIED ENVIRONMENTS”, «IEEE Robotics and Automation Magazine»
Saturday, March 1, 2014
Image Retrieval in Remote Sensing
CBMI 2014 - Special Session:
The proliferation of earth observation satellites, together with their continuously increasing performances, provides today a massive amount of geospatial data. Analysis and exploration of such data leads to various applications, from agricultural monitoring to crisis management and global security.
However, they also raise very challenging problems, e.g. dealing with extremely large and real time geospatial data, or user-friendly querying and retrieval satellite images or mosaics. The purpose of this special session is to address these challenges, and to allow researchers from multimedia retrieval and remote sensing to meet and share their experiences in order to build the remote sensing retrieval systems of tomorrow.
Topics of interest
- Content- and context-based indexing, search and retrieval of RS data
- Search and browsing on RS Web repositories to face the Peta/Zettabyte scale
- Advanced descriptors and similarity metrics dedicated to RS data
- Usage of knowledge and semantic information for retrieval in RS
- Maching learning for image retrieval in remote sensing
- Query models, paradigms, and languages dedicated to RS
- Multimodal / multi-obsevations (sensors, dates, resolutions) analysis of RS data
- HCI issues in RS retrieval and browsing
- Evaluation of RS retrieval systems
- High performance indexing algorithms for RS data
- Summarization and visualization of very large satellite image datasets
- Applications of image retrieval in remote sensing
Many public datasets are available to researchers and can be used to evaluate the contributions related to image retrieval in remote sensing. The UC Merced Land Use Dataset is of particular interest in this context, with 2100 RGB images, 21 classes (http://vision.ucmerced.edu/datasets/landuse.html).
Important dates
- Submission deadline: April, 7th
- Notification to authors: May, 12th
- Camera-ready deadline: May, 20th
Contact
For more information please contact the special session chairs Sébastien Lefèvre (sebastien.lefevre <at> irisa.fr) and Philippe-Henri Gosselin (gosselin <at> ensea.fr)
http://cbmi2014.itec.aau.at/image-retrieval-in-remote-sensing/
Thursday, February 27, 2014
Practical Image & Video Processing Using MATLAB
The Chinese version of the textbook "Practical Image & Video Processing Using MATLAB" (Tsinghua Univ Press) is now available

Sunday, February 23, 2014
12th International Content Based Multimedia Indexing Workshop - Demo submission
Authors are invited to submit demo papers of 4 pages maximum. All peer-reviewed, accepted and registered papers will be published in the CBMI 2014 workshop proceedings to be indexed and distributed by the IEEE Xplore. The demos will be presented at CBMI in a demo session. The submissions are peer reviewed in single blind process, the language of the workshop is English.
Important dates:
- Demo paper submission deadline: March 7, 2014
- Notification of acceptance: March 30, 2014
- Camera-ready papers due: April 14, 2014
- Author registration: April 14, 2014
- Early registration: May 25, 2014
Chair & Contact
For more information please visit http://cbmi2014.itec.aau.at/ and for additional questions, remarks, or clarifications please contact the demo chair László Czúni (email: czuni AT almos DOT vein DOT hu) or cbmi2014@itec.aau.at
Saturday, February 22, 2014
Monday, February 17, 2014
CBMI 2014 - Full paper submission deadline: February 28, 2014
Following the eleven successful previous events of CBMI (Toulouse 1999, Brescia 2001, Rennes 2003, Riga 2005, Bordeaux 2007, London 2008, Chania 2009, Grenoble 2010, Madrid 2011, Annecy 2012, and Veszprem 2013), the 12th International Content Based Multimedia Indexing Workshop aims to bring together communities involved in all aspects of content-based multimedia indexing, retrieval, browsing and presentation. CBMI 2014 will take place in Klagenfurt, in the very south of Austria from June 18th to June 20th 2014. CBMI 2014 is organized in cooperation with IEEE Circuits and Systems Society and ACM SIG Multimedia. Topics of the workshop include but are not limited to visual indexing, audio and multi-modal indexing, multimedia information retrieval, and multimedia browsing and presentation. Additional special sessions are planned in the fields of endoscopic videos and images and multimedia metadata.
Topics:
Topics of interest, grouped in technical tracks, include, but are not limited to:
Visual Indexing
- Visual indexing (image, video, graphics)
- Visual content extraction
- Identification and tracking of semantic regions
- Identification of semantic events
Audio and Multi-modal Indexing
- Audio indexing (audio, speech, music)
- Audio content extraction
- Multi-modal and cross-modal indexing
- Metadata generation, coding and transformation
- Multimedia information retrieval
Multimedia retrieval (image, audio, video, …)
- Matching and similarity search
- Content-based search
- Multimedia data mining
- Multimedia recommendation
- Large scale multimedia database management
Multimedia Browsing and Presentation
- Summarization, browsing and organization of multimedia content
- Personalization and content adaptation
- User interaction and relevance feedback
- Multimedia interfaces, presentation and visualization tools
Paper submission
Authors are invited to submit full-length and special session papers of 6 pages and short (poster) and demo papers of 4 pages maximum. All peer-reviewed, accepted and registered papers will be published in the CBMI 2014 workshop proceedings to be indexed and distributed by the IEEE Xplore. The submissions are peer reviewed in single blind process, the language of the workshop is English.
Best papers of the conference will be invited to submit extended versions of their contributions to a special issue of Multimedia Tools and Applications journal (MTAP).
Important dates:
- Full paper submission deadline:
February 16, 2014extended to February 28, 2014 - Demo paper submission deadline: March 7, 2014
- Notification of acceptance: March 30, 2014
- Camera-ready papers due: April 14, 2014
- Author registration: April 14, 2014
- Early registration: May 25, 2014
Friday, February 14, 2014
Video Friday: Shadow Hand, Table Tennis Death Match, and Happy Valentine's Day

Today is Valentine's Day in many countries around the world. For Valentine's Day, we're posting robot videos, because we love robots. And we know you love robots too, at least a little bit, or you wouldn't be here, right? RIGHT!
Also, you should all watch WALL-E again, because it's one of the greatest robot love stories ever told. Consider it the final required video for your Video Friday.
To decide the fate of humanity (or, you know, whatever), professional table tennis champion Timo Boll will take on a Kuka KR Agilus robot arm next month:
read more at IEEE Spectrum
Friday, February 7, 2014
GRire New Version 0.06
The GRire library is a light-weight but complete framework for implementing CBIR (Content Based Image Retrieval) methods. It contains various image feature extractors, descriptors, classifiers, databases and other necessary tools. Currently, the main objective of the project is the implementation of BOVW (Bag of Visual Words) methods so, apart from the image analysis tools, it offers methods from the field of IR (Information Retrieval), e.g. weighting models such as SMART and Okapi, adjusted to meet the Image Retrieval perspective.
The purpose of the project is to help developers create and distribute their methods and test the performance of their BOVW systems in actual databases with minimum effort and without having to deal with every aspect of the model.
Changelog:
v0.0.6
* Added file blacklisting functionality (through code only)
* "Thumbs.db" file of Windows is automatically blacklisted (caused exceptions before)
* Minor GUI fixes
* Converted doubles to floats -> Half disk size required ** NOT BACKWARD COMPATIBLE **
* Asynchronous loading of data in GUI
* Option for multithreaded operations
* Cache options available (via code only, not GUI yet)
* Fixed "TREC file remaining open" bug
* Minor GUI fixes
Monday, February 3, 2014

OpenCV Performance Measurements on Mobile Devices
Marco A. Hudelist, Claudiu Cobârzan and Klaus Schoeffmann - ICMR 2014
Mobile devices like smartphones and tablets are becoming increasingly capable in terms of processing power. Although they are already used in computer vision, no comparable measurement experiments of the popular OpenCV framework have been made yet. We try to ll this gap by evaluating the performance of a set of typical OpenCV operations, on mobile devices like the iPad Air and iPhone 5S. We compare those results with the performance of a consumer
grade laptop PC (MacBook Pro). Our tests span from simple image manipulation methods to keypoint detection and descriptor extraction as well as descriptor matching. Results show that the top performing device can match the performance of the PC up to 80 percent in specific operations.
Wednesday, January 8, 2014
12th International Content Based Multimedia Indexing Workshop
Following the eleven successful previous events of CBMI (Toulouse 1999, Brescia 2001, Rennes 2003, Riga 2005, Bordeaux 2007, London 2008, Chania 2009, Grenoble 2010, Madrid 2011, Annecy 2012, and Veszprem 2013), the 12th International Content Based Multimedia Indexing Workshop aims to bring together communities involved in all aspects of content-based multimedia indexing, retrieval, browsing and presentation. CBMI 2014 will take place in Klagenfurt, in the very south of Austria from June 18th to June 20th 2014. CBMI 2014 is organized in cooperation with IEEE Circuits and Systems Society and ACM SIG Multimedia. Topics of the workshop include but are not limited to visual indexing, audio and multi-modal indexing, multimedia information retrieval, and multimedia browsing and presentation. Additional special sessions are planned in the fields of endoscopic videos and images and multimedia metadata.
Topics:
Topics of interest, grouped in technical tracks, include, but are not limited to:
Visual Indexing
- Visual indexing (image, video, graphics)
- Visual content extraction
- Identification and tracking of semantic regions
- Identification of semantic events
Audio and Multi-modal Indexing
- Audio indexing (audio, speech, music)
- Audio content extraction
- Multi-modal and cross-modal indexing
- Metadata generation, coding and transformation
- Multimedia information retrieval
Multimedia retrieval (image, audio, video, …)
- Matching and similarity search
- Content-based search
- Multimedia data mining
- Multimedia recommendation
- Large scale multimedia database management
Multimedia Browsing and Presentation
- Summarization, browsing and organization of multimedia content
- Personalization and content adaptation
- User interaction and relevance feedback
- Multimedia interfaces, presentation and visualization tools
Paper submission
Authors are invited to submit full-length and special session papers of 6 pages and short (poster) and demo papers of 4 pages maximum. All peer-reviewed, accepted and registered papers will be published in the CBMI 2014 workshop proceedings to be indexed and distributed by the IEEE Xplore. The submissions are peer reviewed in single blind process, the language of the workshop is English.
Best papers of the conference will be invited to submit extended versions of their contributions to a special issue ofMultimedia Tools and Applications journal (MTAP).
Important dates:
- Paper submission deadline: February 16, 2014
- Notification of acceptance: March 30, 2014
- Camera-ready papers due: April 14, 2014
- Author registration: April 14, 2014
- Early registration: May 25, 2014
Contact
For more information please visit http://cbmi2014.itec.aau.at/ and for additional questions, remarks, or clarifications please contact cbmi2014@itec.aau.at