Christian Forster, Luca Carlone, Frank Dellaert, Davide Scaramuzza, "IMU Preintegration on Manifold for Efficient Visual-Inertial Maximum-a-Posteriori Estimation", Robotics: Science and Systems (RSS), Rome, 2015.
PDF: http://rpg.ifi.uzh.ch/docs/RSS15_Fors...
Supplementary Material: http://rpg.ifi.uzh.ch/docs/RSS15_Fors...
Abstract:
Recent results in monocular visual-inertial navigation (VIN) have shown that optimization-based approaches outperform filtering methods in terms of accuracy due to their capability to relinearize past states. However, the improvement comes at the cost of increased computational complexity. In this paper, we address this issue by preintegrating inertial measurements between selected keyframes. The preintegration allows us to accurately summarize hundreds of inertial measurements into a single relative motion constraint. Our first contribution is a preintegration theory that properly addresses the manifold structure of the rotation group and carefully deals with uncertainty propagation. The measurements are integrated in a local frame, which eliminates the need to repeat the integration when the linearization point changes while leaving the opportunity for belated bias corrections. The second contribution is to show that the preintegrated IMU model can be seamlessly integrated in a visual-inertial pipeline under the unifying framework of factor graphs. This enables the use of a structureless model for visual measurements, further accelerating the computation. The third contribution is an extensive evaluation of our monocular VIN pipeline: experimental results confirm that our system is very fast and demonstrates superior accuracy with respect to competitive state-of-the-art filtering and optimization algorithms, including off-the-shelf systems such as Google Tango.

Tuesday, June 30, 2015
IMU Preintegration on Manifold for Efficient Visual-Inertial Maximum-a-Posteriori Estimation
Monday, June 29, 2015
picsbuffet
picsbuffet is a visual image browsing system to visually explore and search millions of images from stock photo agencies and the like. Similar to map services like Google Maps users may navigate through multiple image layers by zooming and dragging. Zooming in (or out) shows more (or less) similar images from lower (or higher) levels. Dragging the view shows related images from the same level. Layers are organized as an image pyramid which is build using image sorting and clustering techniques. Easy image navigation is achieved because the placement of the images in the pyramid is based on an improved fused similarity calculation using visual and semantic image information. picbuffet also allows to perform searches. After starting an image search the user is automatically directed to a region with suiting results. Additional interesting regions on the map are shown on a heatmap.
picsbuffet 0.9 is the first publicly available version using over 1 million images from fotolia. Currently only the Chrome and Opera browser are supported. Future versions will support more images and other browsers as well. picsbuffet was developed by Radek Mackowiak, Nico Hezel and Prof. Dr. Kai Uwe Barthel at HTW Berlin (University of Applied Science).
picsbuffet could be used with other kind of images such as product photos and the like.
For further information about picsbuffet please contact Kai Barthel: barthel@htw-berlin.de
")

Wednesday, June 24, 2015
An Unsupervised Approach for Comparing Styles of Illustrations
Takahiko Furuya, Shigeru Kuriyama and Ryutarou Ohbuchi
In creating web pages, books, or presentation slides, consistent use of tasteful visual style(s) is quite important. In this paper, we consider the problem of style-based comparison and retrieval of illustrations. In their pioneering work, Garces et al. [2] proposed an algorithm for comparing illustrative style. The algorithm uses supervised learning that relied on stylistic labels present in a training dataset. In reality, obtaining such labels is quite difficult. In this paper, we propose an unsupervised approach to achieve accurate and efficient stylistic comparison among illustrations. The proposed algorithm combines heterogeneous local visual features extracted densely. These features are aggregated into a feature vector per illustration prior to be treated with distance metric learning based on unsupervised dimension reduction for saliency and compactness. Experimental evaluation of the proposed method by using multiple benchmark datasets indicates that the proposed method outperforms existing approaches.

http://www.kki.yamanashi.ac.jp/~ohbuchi/online_pubs/CBMI_2015_Style_Furuya_Kuriyama/CBMI2015_web.pdf
Beyond Vanilla Visual Retrieval
The presentation from professor Jiri Matas @ CBMI 2015
The talk will start with a brief overview of the state of the art in visual retrieval of specific objects. The core steps of the standard pipeline will be introduced and recent development improving both precision and recall as well as the memory footprint will be reviewed. Going off the beaten track, I will present a visual retrieval method applicable in conditions when the query and reference images differ significantly in one or more properties like illumination (day, night), the sensor (visible, infrared) , viewpoint, appearance (winter, summer), time of acquisition (historical, current) or the medium (clear, hazy, smoky). In the final part, I will argue that in image-based retrieval it might be often more interesting to look for most *dissimilar* images of the same scene rather than the most similar ones as conventionally done, as especially in large datasets these are just near duplicates.. As an example of such problem formulation, a method efficiently searching for images with the largest scale difference will be presented. A final demo will for instance show that the method finds surprisingly fine details on landmarks, even those that are hardly noticeable for human.

The presentation from professor Jiri Matas is available here.
Tuesday, June 23, 2015
NOPTILUS Final Experiment
The main objective of this experiment was to evaluate the performance of the extended and enhanced version of the NOPTILUS system on a large-scale, open-sea experiment. Operating in open-sea, especially in oceans, the navigation procedure faces several non-trivial problems, such as strong currents, limited communication, severe weather conditions etc. Additionally, this is the first experiment in which we incorporate different sensor modalities. Half of the squad was equipped with single beams DVLs while the other half employed multi-beam sensors.
In order to tackle the open-sea challenges, the new version of the NOPTILUS system incorporates an advanced motion control module that is capable to compensate strong currents, disturbances and turbulences.
Moreover, the final version of the NOPTILUS system utilizes an improved version of the generic plug-n-play web-system, which allows the operation of larger squads. The developed tool is now capable to split the operation procedure in distinct, non-overlapped, timestamps. Based on the size of the squad, the web-system automatically schedules the transmission of the navigation instructions so as, on the one hand, to meet the available bandwidth requirements, while on the other side of the spectrum, to avoid possible congestion issues.
To the best of our knowledge this is the first time that a heterogeneous squad of AUVs is capable of fully autonomous navigate in an unknown open sea area, in order to map the underwater surface of the benthic environment and simultaneously to track the movements of a moving target, in an cooperative fashion.
MPEG CDVS Awareness Event
24 June 2015, Marriot Hotel Warsaw
Event Description: Recent advances in computer vision techniques have made large-scale visual search applications a reality, but have also highlighted industry's need for a standardized solution ensuring interoperability of devices and applications. MPEG, well known for its multimedia coding and representation standards, responded to this need by developing a new standard in this space, Compact Descriptors for Visual Search (MPEG-7 CDVS). The CDVS standard specifies high-performance, low-complexity, compact descriptors from still images, enabling deployment in low-power handheld devices, transmission over congested networks, and the interoperable design of large-scale visual search applications. The purpose of this event is to present CDVS and demonstrate its deployment in a range of applications, from mobile visual search to video content management in broadcasting. The event is targeted to a wide audience and will be of particular interest to developers of visual search applications, multimedia device and sensor manufacturers, multimedia content creators and broadcasters.
Date & Venue: Wednesday 24th June 2015, 14:00 – 18:00 (during 112th MPEG Meeting) Marriott Hotel, Aleje Jerozolimskie 65/79 - 00697 Warsaw, Poland
Registration: The event is open to the public and free of charge. To register (for logistical purposes only), please send an email to cdvsevent@mpeg7.net

Thursday, June 11, 2015
Machine Vision Algorithm Chooses the Most Creative Paintings in History
Picking the most creative paintings is a network problem akin to finding super spreaders of disease. That’s allowed a machine to pick out the most creative paintings in history.
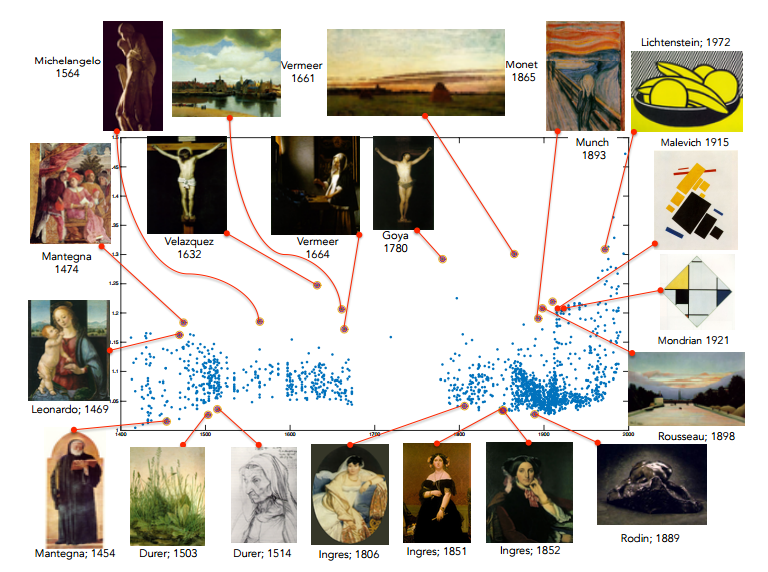
Creativity is one of humanity’s uniquely defining qualities. Numerous thinkers have explored the qualities that creativity must have, and most pick out two important factors: whatever the process of creativity produces, it must be novel and it must be influential.
The history of art is filled with good examples in the form of paintings that are unlike any that have appeared before and that have hugely influenced those that follow. Leonardo’s 1469 Madonna and child with a pomegranate, Goya’s 1780 Christ crucified or Monet’s 1865 Haystacks at Chailly at sunrise and so on. Others paintings are more derivative, showing many similarities with those that have gone before and so are thought of as less creative.
The job of distinguishing the most creative from the others falls to art historians. And it is no easy task. It requires, at the very least, an encyclopedic knowledge of the history of art. The historian must then spot novel features and be able to recognize similar features in future paintings to determine their influence.
Those are tricky tasks for a human and until recently, it would have been unimaginable that a computer could take them on. But today that changes thanks to the work of Ahmed Elgammal and Babak Saleh at Rutgers University in New Jersey, who say they have a machine that can do just this.
They’ve put it to work on a database of some 62,000 pictures of fine art paintings to determine those that are the most creative in history. The results provide a new way to explore the history of art and the role that creativity has played in it
Thursday, June 4, 2015
Baidu caught gaming recent supercomputer performance test

Chinese search engine giant Baidu recently made headlines when its supercomputer reportedly beat out challengers from both Google and Microsoft on the ImageNet image recognition test. However, the company has had to back down from those claims and issue an apology after details emerged suggesting that its success resulted from a scheme to cheat the testing system. As such, Baidu's accomplishment has been stricken from the books and the company has been banned from ImageNet challenges for a full year.
The issue began in Mid-May when Baidu claimed to have scored a record low 4.58% error rate on the test. This exam looks at how well computing clusters can identify objects and locations within photographs -- basically the technology behind Google Photo's auto-tagging feature -- except on large-scale file sets. Microsoft and Google, on the other hand scored 4.94 and 4.8 percent error rates, respectively. That's actually a bit better than the 5 percent average trained humans can achieve and a huge deal for the industry.
However on Tuesday, researchers who actually administered the ImageNet test called shenanigans on Baidu for setting up a series of dummy accounts to brute force a successful test run. The test rules state specifically that contestants are allowed to submit only two sets of test results each week. Baidu apparently set up 30 accounts and spammed the service with 200 requests in six months, 40 of which came over a single five-day period in March. Doing so potentially allowed Baidu engineers to artificially increase the recognition rate by "tuning" their software to the existing test data sets.
"This is pretty bad, and it is exactly why there is a held-out test set for the competition that is hosted on a separate server with limited access," Matthew Zeiler, CEO of AI software company Clarifai, told the Wall Street Journal. "If you know the test set, then you can tweak your parameters of your model however you want to optimize the test set."
In response, Baidu has issued a formal apology for its actions. If, you think apology is a good description for calling the incident a "mistake" and refusing to provide any additional details or explanation as to why it happened.
Wednesday, June 3, 2015
Fail: Computerized Clinical Decision Support Systems for Medical Imaging

Computerized systems that help physicians make clinical decisions fail two-thirds of the time, according to a study published today in the Journal of the American Medical Association (JAMA). With the use of such systems expanding—and becoming mandatory in some settings—developers must work quickly to fix the programs and their algorithms, the authors said. The two-year study, which is the largest of its kind, involved over 3,300 physicians.
Computerized clinical decision support (CDS) systems make recommendations to physicians about next steps in treatment or diagnostics for patients. The physician enters information about the patient and the ailment, and based on a database of criteria, algorithms come up with a score for how appropriate certain next clinical steps would be. These databases of “appropriateness criteria” have been developed by national medical specialty societies and are used across various CDS systems. They aim to reduce overuse of care that can be costly and harmful to patients
But according to the JAMA study, the leading CDS systems don’t work most of the time. The study tracked more than 117,000 orders input by physicians for advanced diagnostic imaging procedures such as magnetic resonance imaging (MRI) and computed tomography (CT). For two-thirds of those orders, the computer program could not come up with any feedback. “Basically it says, ‘I don’t have a guideline for you. I can’t help you,’” says Peter Hussey, a senior policy researcher at RAND Corporation and the lead author of the study. “When that happens two-thirds of the time...the physicians start to get more negative about it.”
That’s a problem, because these computerized decision makers will soon be mandated by the U.S. federal government. The Protecting Access to Medicare Act of 2014 says that, starting in 2017, CDS systems must be allowed to weigh in on whether advanced diagnostic imaging should be ordered for Medicare patients. CDS systems are already used in the private sector as well, but not widely, Hussey says.
The systems’ problems are likely caused by lackluster databases and algorithms that fall short, says Hussey. “There are lots of different kinds of patients with different problems, and the criteria just haven’t been created for some of those. In other cases, it’s likely that the criteria were out there but the CDS tools couldn’t find them,” he explains. “These seem like solvable problems, but we need to get working on this pretty quickly becaue this is going to be mandatory in a couple of years.”
Highly Custom Robot

While some DRC teams received fancy ATLAS robots from DARPA and other teams decided to adapt existing platforms (HUBO and HRP-2, for example) to compete in the Finals, some groups set out to build completely new robots. One of these is Team WALK-MAN from the Italian Institute of Technology (IIT), whose most recent robotic creations include HyQ and COMAN. Before departing to the DRC Finals site in Pomona, Calif., Nikos Tsagarakis, a senior researcher at IIT and WALK-MAN Project Coordinator, spoke with us about his team’s highly customized robot, its mains capabilities, and how it compares to ATLAS.
To design and build WALK-MAN, did you get inspiration from other robots? Which ones?
WALK-MAN was developed as part of the European Commission-funded Project WALK-MAN, and the goal was creating a completely original and new body design, so it is different from any other existing robot we developed so far at IIT. Apart from following our traditional approach to soft robot design by adding joint elasticity to the robot’s joints, WALK-MAN’s hardware is 100 percent new. Its main features include the use of custom designed high-power motor drives able to deliver several kilowatts of peak power at a single joint. We also optimized the design of its body to reduce the inertia and mass and improve the dynamic performance of the robot. A rich sensory system gives us the state of the robot in terms of loads (joint torque sensing) and thermal sensing/fatigue for both the actuators and the electronics. In terms of control, WALK-MAN drives can be controlled in different modes including position, torque, and impedance at rates up to 5 kHz.
How does WALK-MAN compare to ATLAS?
The two robots differ in their actuation system (WALK-MAN is an electrical motor driven robot while ATLAS is a hydraulic system) but are very similar in certain dimensions like height (1.85 m) and shoulder distance (0.8 m). WALK-MAN is lighter (120 kg with backpack) than Atlas (around 180 kg). In terms of capabilities, WALK-MAN joint performance is very close to ATLAS joints. Leg joints can produce torques up to 320 Nm and reach velocities of 11 to 12 radians per second at torques as high as 250 Nm. WALK-MAN arms have more extensive range and can generate torques up to 140 Nm at the shoulder level. We also expect to be a more efficient robot than ATLAS and able to operate for more prolonged periods without recharging.
Facebook uses deep learning as a way of recognizing images on its social network

FACEBOOK IS OPENING a new artificial intelligence lab in Paris after building a dedicated AI team that spans its offices in New York and Silicon Valley.
The New York University professor who oversees the company’s AI work, Yann LeCun, was born and educated in Paris. LeCun tells WIRED that he and the company are interested in tapping the research talent available in Europe. Alongside London, he says, Paris was an obvious choice for a new lab. “We plan to work openly with and invest in the AI research community in France, the EU, and beyond,” he wrote in a blog post announcing the move.
LeCun is one of the researchers at the heart of an AI movement known as deep learning. Since the 1980s, he and a small group of other researchers have worked to build networks of computer hardware that approximate the networks of neurons in the brain. In recent years, the likes of Facebook, Google, and Microsoft have embraced these “neural nets” as a way of handling everything from voice and image recognition to language translation.
Another researcher who bootstrapped this movement, University of Toronto professor Geoff Hinton, is now at Google. Like Facebook, Google is investing heavily in this rapidly evolving technology, and the two companies are competing for a rather small talent pool. After acquiring a deep learning startup called DeepMind, based in the UK and founded by an English researcher named Demis Hassabis, Google already operates a European AI lab of sorts.
Chris Nicholson, founder of the San Francisco-based AI startup Skymind, points out the many of the key figures behind deep learning are European, including not only LeCun, Hinton, and Hassabis, but also University of Montreal professor Yoshua Bengio (though he was educated in Canada). “All of them are now employed by North American organizations,” Nicholson says. “There are a lot of investment gaps in European venture capital, which means that Europe has a lot of ideas and people that either come to America or never make an impact on the mainstream.”
Today, Facebook uses deep learning as a way of recognizing images on its social network, and it’s exploring the technology as a means of personalizing your Facebook News Feed so that you’re more likely to enjoy what you see. The next big step, LeCun says, is natural language processing, which aims to give machines the power to understand not just individual words but entire sentences and paragraphs.
Article From http://www.wired.com/2015/06/facebook-opens-paris-lab-ai-research-goes-global/
From Captions to Visual Concepts and Back
Hao Fang, Saurabh Gupta, Forrest Iandola, Rupesh Srivastava, Li Deng, Piotr Dollar, Jianfeng Gao, Xiaodong He, Margaret Mitchell, John Platt, Lawrence Zitnick, and Geoffrey Zweig
June 2015
Abstract
This paper presents a novel approach for automatically generating image descriptions: visual detectors, language models, and multimodal similarity models learnt directly from a dataset of image captions. We use multiple instance learning to train visual detectors for words that commonly occur in captions, including many different parts of speech such as nouns, verbs, and adjectives. The word detector outputs serve as conditional inputs to a maximum-entropy language model. The language model learns from a set of over 400,000 image descriptions to capture the statistics of word usage. We capture global semantics by re-ranking caption candidates using sentence-level features and a deep multimodal similarity model. Our system is state-of-the-art on the official Microsoft COCO benchmark, producing a BLEU-4 score of 29.1%. When human judges compare the system captions to ones written by other people on our held-out test set, the system captions have equal or better quality 34% of the time.

http://research.microsoft.com/en-us/projects/image_captioning/