

Monday, December 21, 2009
CFP: The Second International Workshop on Mobile Multimedia Processing (WMMP'10)
OVERVIEW
The Second International Workshop on Mobile Multimedia Processing will be held in Istanbul, Turkey, on August 22, 2010, in conjunction with the 20th International Conference on Pattern Recognition (ICPR 2010). This is the follow-up of the successful First International Workshop on Mobile Multimedia Processing held in conjunction with 19th ICPR in Tampa, Florida, 2008. The motivation of this workshop series is to timely address the challenges in applying advanced pattern recognition, signal processing, computer vision and multimedia techniques to mobile systems, given the proliferating market of mobile and portable devices that have been widely spreading in both consumer (e.g. smartphones such as iPhone, music, mobile TV, digital cameras, HDTV) and industrial markets (e.g. control, medical, defense etc.).
One aim of the workshop is to bring together researchers in pattern recognition as well as in mobile interaction, ubiquitous computing, and multimedia. The intended audiences of this workshop are researchers in traditional pattern recognition and media processing techniques wanting to extend their work in the mobile domain, and those researchers in mobile interaction, ubiquitous computing, and cross related fields wanting to explore latest achievements in the pattern recognition field to expand their work.
SCOPE
The motivation of this workshop is to timely address the challenges in applying advanced pattern recognition, signal processing, computer vision and multimedia techniques to mobile systems, given the proliferating market of mobile and portable devices that have been widely spreading in both consumer (e.g. smartphones such as iPhone, music, mobile TV, digital cameras, HDTV) and industrial markets (e.g.
control, medical, defense). The proposed scope of this workshop includes, but is not limited to, the following areas:
- Mobile speech, image and video processing
- Surveillance, biometric, authentication and security technologies in mobile environment
- Mobile visual search
- Mobile image retrieval
- Mobile augmented reality browsers
- Mobile video streaming
- Multimodal pedestrian navigation systems
- Multimedia applications for automotive systems
- Mobile navigation, content retrieval, authentication
- Pervasive computing / context aware methodology and application
- Multimodal interfaces and visualization for mobile devices
- Handheld augmented reality
- Personalization and recommender systems in mobile environment
- Mobile oriented media processing for communication and networking
- Medical applications and bioinformatics in mobile environment
- Entertainment applications in mobile environment
- Mobile multimedia applications in geospatial information systems
DATES AND DEADLINES
Paper submission: April 1, 2010
Author notification: May 1, 2010
ICPR early registration: May 14, 2010
Final camera-ready manuscript due: June 1, 2010
Sunday, December 20, 2009
Paper, peer review, and vested interests [Guest Editorial]
Boggs, S.
This paper appears in: Electrical Insulation Magazine, IEEE
Publication Date: November-December 2009
Volume: 25, Issue: 6
On page(s): 3-3
ISSN: 0883-7554
Digital Object Identifier: 10.1109/MEI.2009.5313703
Current Version Published: 2009-11-20
Abstract
Peer review goes back to at least 1665 with the founding of Philosophical Transactions of the Royal Society. However peer review did not become well established until the middle of the last century. For example, Einstein's 1905 papers in Annalen der Physik were not subjected to a peer review process. The purpose for which peer review was established is not clear. The probable motives include a combination of rationing of (then) very expensive journal pages, catching obvious errors, and at least some degree of quality control on what is published. The question now is "Do past models make sense in the world of the Internet?", as today, on-line published pages are essentially free and continuous on-line review and rebuttal is practical.
Scale-invariant feature transform
For any object in an image, there are many 'features' which are interesting points on the object, that can be extracted to provide a "feature" description of the object. This description extracted from a training image can then be used to identify the object when attempting to locate the object in a test image containing many other objects. It is important that the set of features extracted from the training image is robust to changes in image scale, noise, illumination and local geometric distortion, for performing reliable recognition. Lowe's patented method can robustly identify objects even among clutter and under partial occlusion because his SIFT feature descriptor is invariant to scale, orientation, affine distortion and partially invariant to illumination changes. This section presents Lowe's object recognition method in a nutshell and mentions a few competing techniques available for object recognition under clutter and partial occlusion.
David Lowe's method
SIFT keypoints of objects are first extracted from a set of reference images and stored in a database. An object is recognized in a new image by individually comparing each feature from the new image to this database and finding candidate matching features based on Euclidean distance of their feature vectors. From the full set of matches, subsets of keypoints that agree on the object and its location, scale, and orientation in the new image are identified to filter out good matches. The determination of consistent clusters is performed rapidly by using an efficient hash table implementation of the generalized Hough transform. Each cluster of 3 or more features that agree on an object and its pose is then subject to further detailed model verification and subsequently outliers are discarded. Finally the probability that a particular set of features indicates the presence of an object is computed, given the accuracy of fit and number of probable false matches. Object matches that pass all these tests can be identified as correct with high confidence.
Key stages
Scale-invariant feature detection
Lowe's method for image feature generation called the Scale Invariant Feature Transform (SIFT) transforms an image into a large collection of feature vectors, each of which is invariant to image translation, scaling, and rotation, partially invariant to illumination changes and robust to local geometric distortion. These features share similar properties with neurons in inferior temporal cortex that are used for object recognition in primate vision. Key locations are defined as maxima and minima of the result of difference of Gaussians function applied in scale-space to a series of smoothed and resampled images. Low contrast candidate points and edge response points along an edge are discarded. Dominant orientations are assigned to localized keypoints. These steps ensure that the keypoints are more stable for matching and recognition. SIFT descriptors robust to local affine distortion are then obtained by considering pixels around a radius of the key location, blurring and resampling of local image orientation planes.
Feature matching and indexing
Indexing is the problem of storing SIFT keys and identifying matching keys from the new image. Lowe used a modification of the k-d tree algorithm called the Best-bin-first search method that can identify the nearest neighbors with high probability using only a limited amount of computation. The BBF algorithm uses a modified search ordering for the k-d tree algorithm so that bins in feature space are searched in the order of their closest distance from the query location. This search order requires the use of a heap (data structure) based priority queue for efficient determination of the search order. The best candidate match for each keypoint is found by identifying its nearest neighbor in the database of keypoints from training images. The nearest neighbors are defined as the keypoints with minimum Euclidean distance from the given descriptor vector. The probability that a match is correct can be determined by taking the ratio of distance from the closest neighbor to the distance of the second closest.
Lowe rejected all matches in which the distance ratio is greater than 0.8, which eliminates 90% of the false matches while discarding less than 5% of the correct matches. To further improve the efficiency of the best-bin-first algorithm search was cut off after checking the first 200 nearest neighbor candidates. For a database of 100,000 keypoints, this provides a speedup over exact nearest neighbor search by about 2 orders of magnitude yet results in less than a 5% loss in the number of correct matches.
Cluster identification by Hough transform voting
Hough Transform is used to cluster reliable model hypotheses to search for keys that agree upon a particular model pose. Hough transform identifies clusters of features with a consistent interpretation by using each feature to vote for all object poses that are consistent with the feature. When clusters of features are found to vote for the same pose of an object, the probability of the interpretation being correct is much higher than for any single feature. An entry in a hash table is created predicting the model location, orientation, and scale from the match hypothesis.The hash table is searched to identify all clusters of at least 3 entries in a bin, and the bins are sorted into decreasing order of size.
Each of the SIFT keypoints specifies 2D location, scale, and orientation, and each matched keypoint in the database has a record of the keypoint’s parameters relative to the training image in which it was found. The similarity transform implied by these 4 parameters is only an approximation to the full 6 degree-of-freedom pose space for a 3D object and also does not account for any non-rigid deformations. Therefore, Lowe used broad bin sizes of 30 degrees for orientation, a factor of 2 for scale, and 0.25 times the maximum projected training image dimension (using the predicted scale) for location. The SIFT key samples generated at the larger scale are given twice the weight of those at the smaller scale. This means that the larger scale is in effect able to filter the most likely neighbours for checking at the smaller scale. This also improves recognition performance by giving more weight to the least-noisy scale. To avoid the problem of boundary effects in bin assignment, each keypoint match votes for the 2 closest bins in each dimension, giving a total of 16 entries for each hypothesis and further broadening the pose range.
[edit] Model verification by linear least squares
Each identified cluster is then subject to a verification procedure in which a linear least squares solution is performed for the parameters of the affine transformation relating the model to the image. The affine transformation of a model point [x y]T to an image point [u v]T can be written as below

where the model translation is [tx ty]T and the affine rotation, scale, and stretch are represented by the parameters m1, m2, m3 and m4. To solve for the transformation parameters the equation above can be rewritten to gather the unknowns into a column vector.
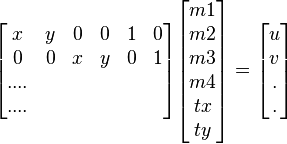
This equation shows a single match, but any number of further matches can be added, with each match contributing two more rows to the first and last matrix. At least 3 matches are needed to provide a solution. We can write this linear system as

where A is a known m-by-n matrix (usually with m > n), x is an unknown n-dimensional parameter vector, and b is a known m-dimensional measurement vector.
Therefore the minimizing vector  is a solution of the normal equation
is a solution of the normal equation

The solution of the system of linear equations is given in terms of the matrix (ATA) − 1AT , called the pseudoinverse of A, by

which minimizes the sum of the squares of the distances from the projected model locations to the corresponding image locations.
Outlier detection
Outliers can now be removed by checking for agreement between each image feature and the model, given the parameter solution. Given the linear least squares solution, each match is required to agree within half the error range that was used for the parameters in the Hough transform bins. As outliers are discarded, the linear least squares solution is re-solved with the remaining points, and the process iterated. If fewer than 3 points remain after discarding outliers, then the match is rejected. In addition, a top-down matching phase is used to add any further matches that agree with the projected model position, which may have been missed from the Hough transform bin due to the similarity transform approximation or other errors.
The final decision to accept or reject a model hypothesis is based on a detailed probabilistic model. This method first computes the expected number of false matches to the model pose, given the projected size of the model, the number of features within the region, and the accuracy of the fit. A Bayesian probability analysis then gives the probability that the object is present based on the actual number of matching features found. A model is accepted if the final probability for a correct interpretation is greater than 0.98. Lowe's SIFT based object recognition gives excellent results except under wide illumination variations and under non-rigid transformations.
Competing methods for scale invariant object recognition under clutter / partial occlusion
RIFT is a rotation-invariant generalization of SIFT. The RIFT descriptor is constructed using circular normalized patches divided into concentric rings of equal width and within each ring a gradient orientation histogram is computed. To maintain rotation invariance, the orientation is measured at each point relative to the direction pointing outward from the center.
G-RIF : Generalized Robust Invariant Feature is a general context descriptor which encodes edge orientation, edge density and hue information in a unified form combining perceptual information with spatial encoding. The object recognition scheme uses neighbouring context based voting to estimate object models.
"SURF : Speeded Up Robust Features" is a high-performance scale and rotation-invariant interest point detector / descriptor claimed to approximate or even outperform previously proposed schemes with respect to repeatability, distinctiveness, and robustness. SURF relies on integral images for image convolutions to reduce computation time, builds on the strengths of the leading existing detectors and descriptors (using a fast Hessian matrix-based measure for the detector and a distribution-based descriptor). It describes a distribution of Haar wavelet responses within the interest point neighbourhood. Integral images are used for speed and only 64 dimensions are used reducing the time for feature computation and matching. The indexing step is based on the sign of the Laplacian,which increases the matching speed and the robustness of the descriptor.
PCA-SIFT and GLOH are variants of SIFT. PCA-SIFT descriptor is a vector of image gradients in x and y direction computed within the support region. The gradient region is sampled at 39x39 locations, therefore the vector is of dimension 3042. The dimension is reduced to 36 with PCA. Gradient location-orientation histogram (GLOH) is an extension of the SIFT descriptor designed to increase its robustness and distinctiveness. The SIFT descriptor is computed for a log-polar location grid with three bins in radial direction (the radius set to 6, 11, and 15) and 8 in angular direction, which results in 17 location bins. The central bin is not divided in angular directions. The gradient orientations are quantized in 16 bins resulting in 272 bin histogram. The size of this descriptor is reduced with PCA. The covariance matrix for PCA is estimated on image patches collected from various images. The 128 largest eigenvectors are used for description.
Wagner et al. developed two object recognition algorithms especially designed with the limitations of current mobile phones in mind. In contrast to the classic SIFT approach Wagner et al. use the FAST corner detector for feature detection. The algorithm also distinguishes between the off-line preparation phase where features are created at different scale levels and the on-line phase where features are only created at the current fixed scale level of the phone's camera image. In addition, features are created from a fixed patch size of 15x15 pixels and form a SIFT descriptor with only 36 dimensions. The approach has been further extended by integrating a Scalable Vocabulary Tree in the recognition pipeline. This allows the efficient recognition of a larger number of objects on mobile phones. The approach is mainly restricted by the amount of available RAM.
Features
The detection and description of local image features can help in object recognition. The SIFT features are local and based on the appearance of the object at particular interest points, and are invariant to image scale and rotation. They are also robust to changes in illumination, noise, and minor changes in viewpoint. In addition to these properties, they are highly distinctive, relatively easy to extract, allow for correct object identification with low probability of mismatch and are easy to match against a (large) database of local features. Object description by set of SIFT features is also robust to partial occlusion; as few as 3 SIFT features from an object are enough to compute its location and pose. Recognition can be performed in close-to-real time, at least for small databases and on modern computer hardware.
Algorithm
Scale-space extrema detection
This is the stage where the interest points, which are called keypoints in the SIFT framework, are detected. For this, the image is convolved with Gaussian filters at different scales, and then the difference of successive Gaussian-blurred images are taken. Keypoints are then taken as maxima/minima of the Difference of Gaussians (DoG) that occur at multiple scales. Specifically, a DoG image 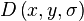 is given by
is given by
 ,
, - where
 is the convolution of the original image
is the convolution of the original image  with the Gaussian blur
with the Gaussian blur  at scale kσ, i.e.,
at scale kσ, i.e.,

Hence a DoG image between scales kiσ and kjσ is just the difference of the Gaussian-blurred images at scales kiσ and kjσ. For scale-space extrema detection in the SIFT algorithm, the image is first convolved with Gaussian-blurs at different scales. The convolved images are grouped by octave (an octave corresponds to doubling the value of σ), and the value of ki is selected so that we obtain a fixed number of convolved images per octave. Then the Difference-of-Gaussian images are taken from adjacent Gaussian-blurred images per octave.
Once DoG images have been obtained, keypoints are identified as local minima/maxima of the DoG images across scales. This is done by comparing each pixel in the DoG images to its eight neighbors at the same scale and nine corresponding neighboring pixels in each of the neighboring scales. If the pixel value is the maximum or minimum among all compared pixels, it is selected as a candidate keypoint.
This keypoint detection step is a variation of one of the blob detection methods developed by Lindeberg by detecting scale-space extrema of the scale normalized Laplacian,that is detecting points that are local extrema with respect to both space and scale, in the discrete case by comparisons with the nearest 26 neighbours in a discretized scale-space volume. The difference of Gaussians operator can be seen as an approximation to the Laplacian, here expressed in a pyramid setting.
Keypoint localization

After scale space extrema are detected (their location being shown in the uppermost image) the SIFT algorithm discards low contrast keypoints (remaining points are shown in the middle image) and then filters out those located on edges. Resulting set of keypoints is shown on last image.
Scale-space extrema detection produces too many keypoint candidates, some of which are unstable. The next step in the algorithm is to perform a detailed fit to the nearby data for accurate location, scale, and ratio of principal curvatures. This information allows points to be rejected that have low contrast (and are therefore sensitive to noise) or are poorly localized along an edge.
Interpolation of nearby data for accurate position
First, for each candidate keypoint, interpolation of nearby data is used to accurately determine its position. The initial approach was to just locate each keypoint at the location and scale of the candidate keypoint.The new approach calculates the interpolated location of the extremum, which substantially improves matching and stability.The interpolation is done using the quadratic Taylor expansion of the Difference-of-Gaussian scale-space function, with the candidate keypoint as the origin. This Taylor expansion is given by:

where D and its derivatives are evaluated at the candidate keypoint and  is the offset from this point. The location of the extremum,
is the offset from this point. The location of the extremum,  , is determined by taking the derivative of this function with respect to
, is determined by taking the derivative of this function with respect to  and setting it to zero. If the offset is larger than 0.5 in any dimension, then that's an indication that the extremum lies closer to another candidate keypoint. In this case, the candidate keypoint is changed and the interpolation performed instead about that point. Otherwise the offset is added to its candidate keypoint to get the interpolated estimate for the location of the extremum. A similar subpixel determation of the locations of scale-space extrema is performed in the real-time implementation based on hybrid pyramids developed by Lindeberg and his co-workers
and setting it to zero. If the offset is larger than 0.5 in any dimension, then that's an indication that the extremum lies closer to another candidate keypoint. In this case, the candidate keypoint is changed and the interpolation performed instead about that point. Otherwise the offset is added to its candidate keypoint to get the interpolated estimate for the location of the extremum. A similar subpixel determation of the locations of scale-space extrema is performed in the real-time implementation based on hybrid pyramids developed by Lindeberg and his co-workers
Discarding low-contrast keypoints
To discard the keypoints with low contrast, the value of the second-order Taylor expansion  is computed at the offset . If this value is less than 0.03, the candidate keypoint is discarded. Otherwise it is kept, with final location
is computed at the offset . If this value is less than 0.03, the candidate keypoint is discarded. Otherwise it is kept, with final location  and scale σ, where
and scale σ, where 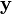 is the original location of the keypoint at scale σ.
is the original location of the keypoint at scale σ.
Eliminating edge responses
The DoG function will have strong responses along edges, even if the candidate keypoint is unstable to small amounts of noise. Therefore, in order to increase stability, we need to eliminate the keypoints that have poorly determined locations but have high edge responses.
For poorly defined peaks in the DoG function, the principal curvature across the edge would be much larger than the principal curvature along it. Finding these principal curvatures amounts to solving for the eigenvalues of the second-order Hessian matrix, H:

The eigenvalues of H are proportional to the principal curvatures of D. It turns out that the ratio of the two eigenvalues, say α is the larger one, and β the smaller one, with ratio r = α / β, is sufficient for SIFT's purposes. The trace of H, i.e., Dxx + Dyy, gives us the sum of the two eigenvalues, while its determinant, i.e., 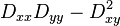 , yields the product. The ratio
, yields the product. The ratio  can be shown to be equal to
can be shown to be equal to  , which depends only on the ratio of the eigenvalues rather than their individual values. R is minimum when the eigenvalues are equal to each other. Therefore the higher the absolute difference between the two eigenvalues, which is equivalent to a higher absolute difference between the two principal curvatures of D, the higher the value of R. It follows that, for some threshold eigenvalue ratio rth, if R for a candidate keypoint is larger than
, which depends only on the ratio of the eigenvalues rather than their individual values. R is minimum when the eigenvalues are equal to each other. Therefore the higher the absolute difference between the two eigenvalues, which is equivalent to a higher absolute difference between the two principal curvatures of D, the higher the value of R. It follows that, for some threshold eigenvalue ratio rth, if R for a candidate keypoint is larger than  , that keypoint is poorly localized and hence rejected. The new approach uses rth = 10.
, that keypoint is poorly localized and hence rejected. The new approach uses rth = 10.
This processing step for suppressing responses at edges is a transfer of a corresponding approach in the Harris operator for corner detection. The difference is that the measure for thresholding is computed from the Hessian matrix instead of a second-moment matrix (see structure tensor).
Orientation assignment
In this step, each keypoint is assigned one or more orientations based on local image gradient directions. This is the key step in achieving invariance to rotation as the keypoint descriptor can be represented relative to this orientation and therefore achieve invariance to image rotation.
First, the Gaussian-smoothed image 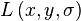 at the keypoint's scale σ is taken so that all computations are performed in a scale-invariant manner. For an image sample
at the keypoint's scale σ is taken so that all computations are performed in a scale-invariant manner. For an image sample  at scale σ, the gradient magnitude,
at scale σ, the gradient magnitude, 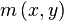 , and orientation,
, and orientation,  , are precomputed using pixel differences:
, are precomputed using pixel differences:

The magnitude and direction calculations for the gradient are done for every pixel in a neighboring region around the keypoint in the Gaussian-blurred image L. An orientation histogram with 36 bins is formed, with each bin covering 10 degrees. Each sample in the neighboring window added to a histogram bin is weighted by its gradient magnitude and by a Gaussian-weighted circular window with a σ that is 1.5 times that of the scale of the keypoint. The peaks in this histogram correspond to dominant orientations. Once the histogram is filled, the orientations corresponding to the highest peak and local peaks that are within 80% of the highest peaks are assigned to the keypoint. In the case of multiple orientations being assigned, an additional keypoint is created having the same location and scale as the original keypoint for each additional orientation.
Keypoint descriptor
Previous steps found keypoint locations at particular scales and assigned orientations to them. This ensured invariance to image location, scale and rotation. Now we want to compute a descriptor vector for each keypoint such that the descriptor is highly distinctive and partially invariant to the remaining variations such as illumination, 3D viewpoint, etc. This step is performed on the image closest in scale to the keypoint's scale.
First a 4x4 array of histograms with 8 bins each is created. These histograms are computed from magnitude and orientation values of samples in a 16 x 16 region around the keypoint such that each histogram contains samples from a 4 x 4 subregion of the original neighborhood region. The magnitudes are further weighted by a Gaussian function with σ equal to 1.5 times the scale of the keypoint. The descriptor then becomes a vector of all the values of these histograms. Since there are 4 x 4 = 16 histograms each with 8 bins the vector has 128 elements. This vector is then normalized to unit length in order to enhance invariance to affine changes in illumination. To reduce the effects of non-linear illumination a threshold of 0.2 is applied and the vector is again normalized.
Although the dimension of the descriptor, i.e. 128, seems high descriptors with lower dimension than this don't perform as well across the range of matching tasks and the computational cost remains low due to the approximate BBF (see below) method used for finding the nearest-neighbor. Longer descriptors continue to do better but not by much and there is an additional danger of increased sensitivity to distortion and occlusion. It is also shown that feature matching accuracy is above 50% for viewpoint changes of up to 50 degrees. Therefore SIFT descriptors are invariant to minor affine changes. To test the distinctiveness of the SIFT descriptors, matching accuracy is also measured against varying number of keypoints in the testing database, and it is shown that matching accuracy decreases only very slightly for very large database sizes, thus indicating that SIFT features are highly distinctive.
Comparison of SIFT features with other local features
There has been an extensive study done on the performance evaluation of different local descriptors, including SIFT, using a range of detectors.The main results are summarized below:
- SIFT and SIFT-like GLOH features exhibit the highest matching accuracies (recall rates) for an affine transformation of 50 degrees. After this transformation limit, results start to become unreliable.
- Distinctiveness of descriptors is measured by summing the eigenvalues of the descriptors, obtained by the Principal components analysis of the descriptors normalized by their variance. This corresponds to the amount of variance captured by different descriptors, therefore, to their distinctiveness. PCA-SIFT (Principal Components Analysis applied to SIFT descriptors), GLOH and SIFT features give the highest values.
- SIFT-based descriptors outperform other local descriptors on both textured and structured scenes, with the difference in performance larger on the textured scene.
- For scale changes in the range 2-2.5 and image rotations in the range 30 to 45 degrees, SIFT and SIFT-based descriptors again outperform other local descriptors with both textured and structured scene content.
- Performance for all local descriptors degraded on images introduced with a significant amount of blur, with the descriptors that are based on edges, like shape context, performing increasingly poorly with increasing amount blur. This is because edges disappear in the case of a strong blur. But GLOH, PCA-SIFT and SIFT still performed better than the others. This is also true for evaluation in the case of illumination changes.
The evaluations carried out suggests strongly that SIFT-based descriptors, which are region-based, are the most robust and distinctive, and are therefore best suited for feature matching. However, most recent feature descriptors such as SURF have not been evaluated in this study.
SURF has later been shown to have similar performance to SIFT, while at the same time being much faster.
Recently, a slight variation of the descriptor employing an irregular histogram grid has been proposed that significantly improves its performance. Instead of using a 4x4 grid of histogram bins, all bins extend to the center of the feature. This improves the descriptor's robustness to scale changes.
33rd Annual ACM SIGIR Conference
SIGIR is the major international forum for the presentation of new research results and for the demonstration of new systems and techniques in the broad field of information retrieval (IR). The Conference and Program Chairs invite all those working in areas related to IR to submit original papers, posters, and proposals for tutorials, workshops, and demonstrations of systems. SIGIR 2010 welcomes contributions related to any aspect of IR theory and foundation, techniques, and applications. Relevant topics include, but are not limited to:
-
Document Representation and Content Analysis (e.g., text representation, document structure, linguistic analysis, non-English IR, cross-lingual IR, information extraction, sentiment analysis, clustering, classification, topic models, facets)
-
Queries and Query Analysis (e.g., query representation, query intent, query log analysis, question answering, query suggestion, query reformulation)
-
Users and Interactive IR (e.g., user models, user studies, user feedback, search interface, summarization, task models, personalized search)
-
Retrieval Models and Ranking (e.g., IR theory, language models, probabilistic retrieval models, feature-based models, learning to rank, combining searches, diversity)
-
Search Engine Architectures and Scalability ( e.g., indexing, compression, MapReduce, distributed IR, P2P IR, mobile devices)
-
Filtering and Recommending (e.g., content-based filtering, collaborative filtering, recommender systems, profiles)
-
Evaluation (e.g., test collections, effectiveness measures, experimental design)
-
Web IR and Social Media Search (e.g., link analysis, query logs, social tagging, social network analysis, advertising and search, blog search, forum search, CQA, adversarial IR)
-
IR and Structured Data (e.g., XML search, ranking in databases, desktop search, entity search)
-
Multimedia IR (e.g., Image search, video search, speech/audio search, music IR)
-
Other Applications (e.g., digital libraries, enterprise search, vertical search, genomics IR, legal IR, patent search, text reuse)
IMPORTANT DATES:
-
15 Jan 2010 : Abstracts for full research papers due
-
22 Jan 2010 : Full research paper submissions due
-
29 Jan 2010 : Workshop proposals due
-
12 Feb 2010 : Posters, demonstration, and tutorial proposals due
-
4 Mar 2010 : Notification of workshop acceptances
-
7 Mar 2010 : Doctoral consortium proposals due
-
24 Mar 2010 : All other acceptance notifications
-
19-23 Jul 2010 : Conference
Content Guidelines
Follow this link.
Submission
Use: http://sigir2010.confmaster.net/.
GENERAL CO-CHAIRS:
-
Fabio Crestani, University of Lugano, Switzerland
-
Stephane Marchand-Maillet, University of Geneva, Switzerland
TECHNICAL PROGRAM CO-CHAIRS:
-
Hsin-Hsi Chen, National Taiwan University, Taipei, Taiwan
-
Efthimis N. Efthimiadis, University of Washington, WA, USA
-
Jacques Savoy, University of Neuchatel, Switzerland
Information on how to submit will be available by mid-December, 2009.
For other details, please see the conference web site: http://www.sigir2010.org/
Saturday, December 19, 2009
New Version Of img(Rummager)
New Features
1. Evaluate the results using the new Mean Normalized Retrieval Order
2. BTDH descriptor bug fixed


Thursday, December 17, 2009
Use pictures to search the web
A picture is worth a thousand words.No need to type your search anymore. Just take a picture.
![]()
Find out what businesses are nearby.Just point your phone at a store.
This is just the beginning - it's not quite perfect yet.Works well for some things, but not for all.

Your pictures, your control.Turn on 'visual search history' to view or share your pictures at any time. Turn it off to discard them once the search is done.
Learn more in the Google Mobile Help Center
Go to Android market from your phone and search for "Google Goggles".
Available on phones that run Android 1.6+. Learn more






Visual observation and analysis of animal and insect behavior
A one day workshop to be held in conjunction with the
20th International Conference on Pattern Recognition (ICPR 2010)
Istanbul, Turkey
August 22, 2010
and sponsored by the EU ChiRoPing project: Developing versatile and robust perception using sonar systems that integrate active sensing, morphology and behaviour.
There has been an enormous amount of research on analysis of video data of humans, but relatively little on visual analysis of other organisms. The goal of this workshop is to stimulate and bring together the current research in this area, and provide a forum for researchers to share expertise. As we want to make this more of a discussion workshop, we encourage work-in-progress presentations. Reviewing will be lightweight and only abstracts will be circulated to attendees.
The issues that the research will address include:
- detection of living organisms
- organism tracking and movement analysis
- dynamic shape analysis
- classification of different organisms (eg. by subspecies)
- assessment of organism behavior or behavior changes
- size and shape assessment
- counting
- health monitoring
These problems can be applied to a variety of species at different sizes, such as fruit and house flies, crickets, cockroaches and other insects, farmed and wild fish, mice and rats, commercial farm animals such as poultry, cows and horses, and wildlife monitoring, etc. One aspect that they all have in common is video data.
Submission Information
Submit a 4 page extended abstract in English, in PDF, by email to rbf@inf.ed.ac.uk by April 1, 2010. The extended abstracts (PDF) should be anonymous. Include in your email the name(s) of the author(s), institutional affiliation, complete mailing address, international phone and fax numbers. The papers presented at the workshop will be published in the workshop notes, for distribution to the participants and linked to this page after the workshop.
Important Dates
Submission Deadline
April 1, 2010
Acceptance Notification
May 1, 2010
Revised Abstract Deadline
June 1, 2010
Registration Information
On-line registration of workshops will be available via the ICPR 2010 web page. It is not necessary to register for the full conference to attend the workshop.
Wednesday, December 16, 2009
Displaying Binary Images and Barcode
Article from The Code Project
One of my friends was asking me how to display barcodes in ASP.NET. There is a great Open Source code written by Bart De Smet which can return a bar code image from a bar code string; you could see his article here. I have just added to it a small option of whether or not to display the code under the bar code. The library returns an Image. I thought, adding the display of the bar code from the bar code string value to RBMBinaryImage would be cool.
Background
In the last version of RBMBinaryImage on CodeProject, some people pointed out that the control worked in Visual Studio perfectly but not well on some servers. I place here a solution for this problem posted by Louis, on of the control users on my site for the RBMBinaryImage, for users using the old version.
- Open IIS and open the properties for the website you want the handler to work for.
- Open Handler mappings and select a file extension which is served by ASP.NET, like .aspx, and click Edit.
- Copy the file that's used over there (should be %windir%\Microsoft.NET\Framework\v2.0.50727\aspnet_isapi.dll).
- Close the dialog and click Add Script Map... to add a new one. Put the copied value in the right textbox, and fill in .rbm as the extension you want to be handled - uncheck the option "Verify that file exists" when mapping the application extensions.
- Next, close all open boxes by clicking OK, and you should be ready to go.
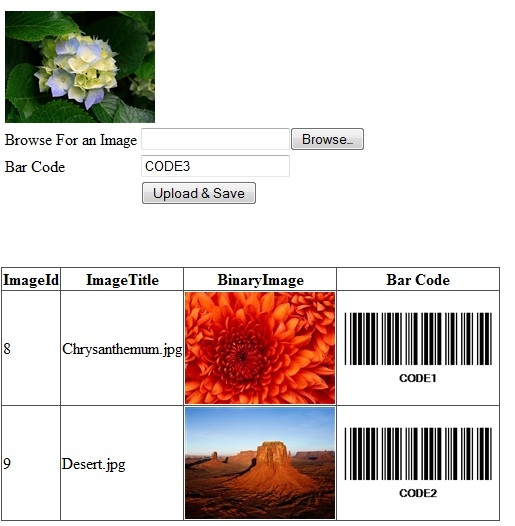
In the new version of the control, we can display a barcode as an image. Shown below is a screenshot:
Connecting the Dots between Color Vision Experiments
John J. McCann
Thomas Young, James Clerk Maxwell and Herman von Helmholtz describe human color as the trichromatic response to the quanta catch of three retinal receptors, at a pixel. In the 204 years since Young’s trichromatic suggestion, there have been many hundreds, if not thousands, of vision experiments that demonstrate that two patches of retina stimulated by identical spectral radiances do not generate identical appearances. The usual description of these experiments is they are illusions
 .
.
There is an alternative way to think about color vision, as succinctly put by Leonardo da Vinci: “Colors are most beautiful in the presence of their opposites”. In this alternative construct, color illusions are simply color appearances synthesized from spatial comparisons. For example, color constancy experiments show that objects have nearly constant appearance, despite significant changes in the spectral illumination. Color appearance correlates with the spatial computation the object’s reflectance, using cone sensitivity functions.
This talk will discuss a wide variety of dramatic color experiments, including: constancy, adaptation, assimilation, Maximov’s shoe box, Land’s red and white photography, color-gamut mapping and color from rod/Lcone interactions. All these experiments make a convincing argument that human vision differs from film and electronic sensors. Vision works by making spatial comparisons. We will discuss whether these experiments are in fact illusions, or the signature of vision’s underlying mechanisms. As well, we will discuss whether many small modifications of trichromatic theory can account for illusions, or if this possibility is a delusion.
http://web.mac.com/mccanns/Site/Xerox_Distinguished_Lecturer.html
Tuesday, December 15, 2009

YouTube Statistics
Total videos uploaded as of March 17th 2008: 78.3 Million
Videos uploaded per day: over 200,000
A wildcard search on YouTube ("*") has given us the following "total results" (which approximates the total number of videos on YouTube)
January 28th 2008: 70 million
March 13th 2008: 77.4 million
March 17th 2008: 78.3 million
These numbers suggest that there are now at least150,000 and likely over 200,000 videos published everyday on YouTube.
The following statistics are derived from a *nearly* random sample of 232 videos on Wednesday, March 12th 2007.
Method: Every 2 hours, one of 8 researchers loaded the "Most Recent" videos on YouTube and analyzed the first 20 videos (the most recently added at that moment). This was done to eliminate the sampling bias of different times. Almost 20 videos were watched every 2 hours as they were uploaded to YouTube. 8 videos were blocked or removed before they could be viewed by the researchers, giving us the total of 232.
YouTube by Category: (Click here for a Tag Cloud Visualization)
Music: 19.8%
Entertainment: 19.0%
People & Blogs: 14.2%
Comedy: 13.4%
Sports: 6.9%
Education: 6.0%
Autos: 5.2%
Film: 4.7%
HowTo: 2.6%
News: 2.6%
Pets: 2.2%
Science: 2.2%
Travel: 1.3%
Most commonly used tags: (the following were the only tags used 4 or more times in the sample)
video, sexy, sex, music, rock, rap, funny, news, pop, dance, film, short, TV
Average Video Length: 2 minutes 46.17 seconds
Time it would take to view all of the material on YouTube (as of March 17th 2008): 412.3 years
Average Age of Uploader: 26.57
(note that this is not the average age of anybody who has ever uploaded a video, but the average age of active uploading)
Unambiguously User-Generated (amateur): 80.3%
Professional: 14.7%
Commercial Content Uploaded as percentage of Total Uploads: 4.7%
Vlogs Uploaded as percentage of Total Uploads: 4.7%
Percentage of videos that are probably in violation of copyright: 12%
Uploads by Country:
(Note: these statistics assume that upload traffic is consistent throughout a 24 hour period. For example the majority of YouTube videos are from the USA between 8pm - midnight CDT. If overall upload traffic is higher at this time than the early morning hours when USA percentage is low, then the USA may account for a higher percentage of total uploads. The reverse might also be true.)
USA: 34.5%
UK: 6.9%
Philippines: 3.9%
Turkey: 3.4%
Spain: 3.4%
Canada: 3.0%
Brazil: 3.0%
Germany: 2.6%
France: 2.6%
Mexico: 2.6%
Australia: 2.6%
Uploads by Language:
(same limitations as above for uploads by country apply here as well)
English: 48.1%
Spanish: 13.6%
Dutch: 3.9%
German: 2.9%
Portuguese: 2.9%
Saturday, December 12, 2009
GazoPa
![]()
GazoPa is a similar image search service on the web in open beta by Hitachi. Users can search images from the web based on user’s own photo, drawings, images found on the web and keywords. GazoPa enables users to search for a similar image from characteristics such as a color or a shape extracted from an image itself. There are abundant quantities of images on the web, however many of these simply cannot be described by keywords. Since GazoPa uses image features to search other similar images, a vast range of images can be retrieved from the web. GazoPa is a new visual search service that can navigate users to new territories on the web.
Thursday, December 10, 2009
The 4th International Conference on Multimedia and Ubiquitous Engineering (MUE 2010)
Recent advances in pervasive computers, networks, telecommunication, and information technology, along with the proliferation of multimedia-capable mobile devices, such as laptops, portable media players, personal digital assistants, and cellular telephones, have stimulated the development of intelligent and pervasive multimedia applications in a ubiquitous environment. The new multimedia standards (for example, MPEG-21) facilitate the seamless integration of multiple modalities into interoperable multimedia frameworks, transforming the way people work and interact with multimedia data. These key technologies and multimedia solutions interact and collaborate with each other in increasingly effective ways, contributing to the multimedia revolution and having a significant impact across a wide spectrum of consumer, business, healthcare, education, and governmental domains. This conference provides an opportunity for academic and industry professionals to discuss recent progress in the area of multimedia and ubiquitous environment including models and systems, new directions, novel applications associated with the utilization and acceptance of ubiquitous computing devices and systems.
The goals of this conference are to provide a complete coverage of the areas outlined and to bring together the researchers from academic and industry as well as practitioners to share ideas, challenges, and solutions relating to the multifaceted aspects of this field.
The conference includes, but is not limited to, the areas listed below:
- Track 1: Ubiquitous Computing and Beyond
- Ubiquitous Computing and Technology
- Context-Aware Ubiquitous Computing
- Parallel/Distributed/Grid Computing
- Novel Machine Architectures
- Semantic Web and Knowledge Grid
- Smart Home and Generic Interfaces
- Track 2: Multimedia Modeling and Processing
- AI and Soft Computing in Multimedia
- Computer Graphics and Simulation
- Multimedia Information Retrieval (images, videos, hypertexts, etc.)
- Internet Multimedia Mining
- Medical Image and Signal Processing
- Multimedia Indexing and Compression
- Virtual Reality and Game Technology
- Current Challenges in Multimedia
- Track 3: Ubiquitous Services and Applications
- Protocols for Ubiquitous Services
- Ubiquitous Database Methodologies
- Ubiquitous Application Interfaces
- IPv6 Foundations and Applications
- Smart Home Network Middleware
- Ubiquitous Sensor Networks / RFID
- U-Commerce and Other Applications
- Databases and Data Mining
- Track 4: Multimedia Services and Applications
- Multimedia RDBMS Platforms
- Multimedia in Telemedicine
- Multimedia Embedded Systems
- Entertainment Industry
- E-Commerce and E-Learning
- Novel Multimedia Applications
- Computer Graphics
- Track 5: Multimedia and Ubiquitous Security
- Security in Commerce and Industry
- Security in Ubiquitous Databases
- Key Management and Authentication
- Privacy in Ubiquitous Environment
- Sensor Networks and RFID Security
- Multimedia Information Security
- Forensics and Image Watermarking
- Track 6: Other IT and Multimedia Applications
Important Dates
December 14, 2009 Workshop/Special session proposal
January 28, 2010 Paper submission deadline
February 28, 2010 Notification of acceptance
March 20, 2010 Camera-ready paper due
March 20, 2010 Presenting author registration due
June 28-30, 2010 Conference events
Paper Publication
All accepted papers will be included in the conference proceeding published by IEEE Press (IEEE eXpress Conference Publishing group) and will be included in the IEEE Xplorer. Outstanding papers will be invited for extension and publication in several journal special issues.
Wednesday, December 9, 2009
Image retrieval from the web using multiple features
Title: Image retrieval from the web using multiple features
Author(s): A. Vadivel, Shamik Sural, A.K. Majumdar
Journal: Online Information Review
DOI: 10.1108/14684520911011061
Publisher: Emerald Group Publishing Limited
Abstract:
Purpose – The main obstacle in realising semantic-based image retrieval from the web is that it is difficult to capture semantic description of an image in low-level features. Text-based keywords can be generated from web documents to capture semantic information for narrowing down the search space. The combination of keywords and various low-level features effectively increases the retrieval precision. The purpose of this paper is to propose a dynamic approach for integrating keywords and low-level features to take advantage of their complementary strengths.
Design/methodology/approach – Image semantics are described using both low-level features and keywords. The keywords are constructed from the text located in the vicinity of images embedded in HTML documents. Various low-level features such as colour histograms, texture and composite colour-texture features are extracted for supplementing keywords.
Findings – The retrieval performance is better than that of various recently proposed techniques. The experimental results show that the integrated approach has better retrieval performance than both the text-based and the content-based techniques.
Research limitations/implications – The features of images used for capturing the semantics may not always describe the content.
Practical implications – The indexing mechanism for dynamically growing features is challenging while practically implementing the system.
Originality/value – A survey of image retrieval systems for searching images available on the internet found that no internet search engine can handle both low-level features and keywords as queries for retrieving images from WWW so this is the first of its kind.
IEEE International Conference on Image Processing (ICIP 2010)
The International Conference on Image Processing (ICIP), sponsored by the IEEE Signal Processing Society, is the premier forum for the presentation of technological advances and research results in the fields of theoretical, experimental, and applied image and video processing. ICIP-2010, the seventeenth in the series that has been held annually since 1994, will bring together leading engineers and scientists in image processing from around the world. Research frontiers in fields ranging from traditional image processing applications to evolving multimedia and video technologies are regularly advanced by results first reported in ICIP technical sessions.
Topics of interest for submissions include, but are not limited to:
* Image/Video Coding and Transmission
* Image/Video Processing and Analysis
* Image Formation
* Image Scanning, Printing, Display and Color
* Image/Video Storage, Retrieval, and Authentication
* Applications
Paper Submission
Prospective authors are invited to submit extended summaries of not more than four (4) pages including results, figures and references. Papers will be accepted only by electronic submission through the conference web site. Prospective authors without web access should contact one of the Technical Program Chairs well before the submission deadline.
* Submission of full-length papers: January 25, 2010
* Notification of acceptance: April 26, 2010
* Submission of camera-ready papers: May 24, 2010
Proposals for Tutorials and Special Sessions
Tutorials will be held on Sunday, September 12, 2010. Proposals for tutorials must include a title, an outline of the tutorial and its motivation, contact information for the presenter(s), and a short description of the material to be covered. Proposals for tutorials should be submitted to the Tutorial Chair S.C. Chan (scchan@eee.hku.hk) before January 11, 2010.
ICIP-2010 will include a number of special sessions. Proposals for special sessions must include a title, contact information for the session chair(s), and a list of authors who have been or will be contacted to present papers if the session is accepted. Proposals for special sessions should be submitted to the Special Sessions Co-Chair Oscar Au (eeau@ee.ust.hk) before December 11, 2009.
http://www.icip2010.org/
Tuesday, December 8, 2009
Visual Studio Virtual Lab
Build data-driven Web applications – fast
Virtual Labs are short, online, interactive, 30- to 90-minute demos. No download, installation or configuration required.
ASP.NET Dynamic Data provides a framework that lets you quickly build a functional data-driven application, based on a LINQ to SQL Server or Entity Framework data model. It also adds great flexibility and functionality to the DetailsView, FormView, GridView, and ListView controls with smart validation and the ability to easily change the display of these controls using templates. In this lab you'll learn how to create a data-driven Web application, add validation to the data model and customize ASP.NET Dynamic Data rendering, pages and fields.
Introduction to the .NET Framework Client Profile
The .NET Framework Client Profile was created in response to feedback, from many customers, that indicated that a smaller framework was needed specifically for Client Applications. The Client Profile is a subset of assemblies already contained within .NET Framework 3.5 Service Pack 1. After completing this lab, you’ll be better able to target your client projects to the .NET Framework 3.5 Client Profile and verify which assembly references are not included in the Client Profile.
Develop an Outlook Add-In
Create applications that are more familiar to end-users with office-applications. Add-ins make it a snap to build your own features into Microsoft Office applications. Visual Studio Tools for Office, an integral technology of Visual Studio 2008, includes features that simplify add-in development. Once you’ve completed this lab, you’ll know how to bind Ribbon Events to WCF Service methods, create form regions and host a Windows Presentation Framework Custom Control.
Build outstanding end-user experiences with Windows Presentation Foundation (WPF)
WPF provides a unified framework for building applications and high-fidelity experiences in Windows that blend together application UI, documents and media content, while exploiting the full power of the local computing hardware. WPF was created to allow developers to more easily build the types of rich applications that were difficult to build with Windows Forms, the type that required a range of other technologies that were often hard to integrate.
Work through this lab, and you’ll learn how to use Visual Studio 2008 Designer to build a WPF client application, see how LINQ features can be used against a Microsoft SQL Server database, see how to access a WCF-based service after generating a Service Reference and put some of the new language features of C# to work.
Silverlight™ Monster Factory – Using a XAML Template
Microsoft Silverlight is a cross-browser, cross-platform plug-in for delivering the next generation of .NET-based media experiences and rich interactive applications for the Web. Silverlight offers a flexible programming model that supports AJAX, Visual Basic, C#, Python and Ruby, and integrates with existing Web applications. Silverlight supports fast, cost-effective delivery of high-quality video to major browsers running on the Mac OS or Windows.
In this lab, you will use Expression Design and Visual Studio 2008 to build a monster factory Web site, and also learn how to create XAML pictures and consume them using Silverlight and JavaScript from a Web site.
Visual Studio 2010 Beta
Set your ideas free
Create what you can imagine, build on the strengths of your team, and open up new possibilities.
- New prototyping, modeling, and visual design tools enable you to create innovative applications for Windows and the Web
- Create a shared vision as a foundation for creativity with SketchFlow ,in Microsoft Expression® Studio , and Team Foundation Server
- Take advantage of new opportunities & capabilities offered by multi-core programming and cloud development tools
Simplicity through integration
A single integrated development environment that takes your skills further and adjusts to the way you work.
- Complete all your coding, modeling, testing, debugging, and deployment work without leaving the Visual Studio 2010 environment
- Use existing standards and skills to target a growing number of application types including Microsoft SharePoint® and Windows® Azure™
- Work your way through multi-monitor support, partner extensions, and a new editor.
Quality tools help ensure quality results
Powerful testing tools with proactive project management features help you build the right app the right way.
- Use the new IntelliTrace debugger to isolate the point of failure within a recorded application history.
- Stay ahead of the curve with proactive project management tools including new reports, dashboards, and planning worksheets.
- Know that you’ve built the right application the right way with manual and automated testing tools.
http://www.microsoft.com/visualstudio/en-us/products/2010/default.mspx
Monday, December 7, 2009
13th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI2010)
MICCAI 2010, the 13th International Conference on Medical Image Computing and Computer Assisted Intervention, will be held from 20th to 24th September 2010 in Beijing, China. The venue for MICCAI 2010 is the China National Convention Center (CNCC). Located in the Beijing Olympic Green, the CNCC is right next to the Bird's Nest (China National Stadium), the Water Cube (National Aquatics Center) and the National Indoor Stadium.
Topics
Topics to be addressed in MICCAI 2010 include, but are not limited to:
- General Medical Image Computing
- Computer Assisted Interventional Systems and Robotics
- Visualization and Interaction
- General Biological Image Computing
- Brain and Neuroscience Image Computing
- Computational Anatomy (statistics on anatomy)
- Computational Physiology (virtual organs)
- Innovative Clinical/Biological Applications and Surgical Procedures
Submission of papers
We invite electronic submissions for MICCAI 2010 (LNCS style, double blind review) of up to 8-page papers for oral or poster presentation. Papers will be reviewed by members of the programme review committee and assessed for quality and best means of presentation. Besides advances in methodology, we would also like to encourage submission of papers that demonstrate clinical relevance, clinical applications, and validation studies.
Proposals for Tutorials and Workshops
Tutorials will be held and will complement and enhance the scientific programme of MICCAI 2010. The purpose of the tutorials is to provide educational material for training new professionals in the field including students, engineers, clinicians and new researchers. The purpose of the workshops is to provide a comprehensive forum on topics that will not be fully explored during the main conference.
Executive Committee
General Chair/Co-Chairs
Tianzi Jiang, Institute of Automation, Beijing, China (Chair)
Alan Colchester, University of Kent, UK
Jim Duncan, Yale University, USA
Programme Chair/Co-Chairs
Max Viergever, Utrecht University & UMC Utrecht, The Netherlands (Chair)
Nassir Navab, TU München, Germany
Josien Pluim, University Medical Center Utrecht, The Netherlands
Workshop Chair/Co-Chairs
Bram van Ginneken, Radboud University Nijmegen, The Netherlands (Chair)
Yong Fan, Institute of Automation, Beijing, China
Polina Golland, Massachusetts Institute of Technology, USA
Tim Salcudean, University of British Columbia, Canada
Tutorial Chair/Co-Chairs
Dinggang Shen, University of North Carolina, USA (Chair)
Alejandro Frangi, Universitat Pompeu Fabra, Barcelona, Spain
Gabor Szekely, ETH Zurich, Switzerland
http://www.miccai2010.org/index.php?option=com_content&view=article&id=106&Itemid=187
Show me the pictures: better format for image results
I love when I get images back in my Google search results. There's no better way to quickly understand the difference between an ocelot and a clouded leopard. But sometimes I want to see more images to really make sure I've identified the right jungle cat.
Over the next twenty-four hours we're rolling out a new format for image universal results. When we're confident that we have great image results, we'll now show a larger image and additional smaller images alongside. With this new layout we're able to show you more pictures than before, so you have more to choose from. As always, you can click on an image to see it full size in the original webpage. 
http://googleblog.blogspot.com/2009/12/show-me-pictures-better-format-for.htmlgoogleblog.blogspot.com
Subscribe to:
Comments (Atom)